Here, We provide Database Management System GTU Paper Solution Winter 2020. Read the Full DBMS gtu paper solution given below.
DBMS GTU Old Paper Winter 2020 [Marks : 56] : Click Here
(a) Define following terms.
1) Schema 2) Database Management System 3) Physical Data independence
- Schema: A schema is a logical description of the entire database. It defines the structure of the database, including the tables, relationships between tables, and constraints. A schema provides a blueprint for the database, outlining the different types of data that can be stored and the rules for organizing and accessing that data.
- Database Management System (DBMS): A database management system (DBMS) is a software system that allows users to define, create, maintain, and control access to a database. DBMS provides an interface for users to interact with the database and perform operations such as adding, modifying, and deleting data. It also ensures the integrity of the data by enforcing rules and constraints.
- Physical Data Independence: Physical data independence is the ability to modify the physical storage structures of the database without affecting the conceptual schema or application programs. This means that the user is shielded from the details of how the data is physically stored on the disk. Any changes made to the physical storage structures should not affect the applications or the logical organization of the data. This type of independence is important because it allows for easier maintenance and modification of the database.
(b) Describe tasks performed by the Database Administrator.
A Database Administrator (DBA) is responsible for managing the organization’s database systems. The tasks performed by the DBA include:
- Database Design: The DBA is responsible for designing the database schema and defining the relationships between tables. They must ensure that the database is organized efficiently and can handle the expected workload.
- Database Installation and Configuration: The DBA is responsible for installing and configuring the database software on the server. They must ensure that the software is configured to operate optimally and that all security protocols are in place.
- Data Backup and Recovery: The DBA is responsible for creating and maintaining backups of the database. They must ensure that the backup strategy is effective and that the database can be restored quickly in the event of a failure.
- Performance Tuning: The DBA must monitor the performance of the database system and make necessary adjustments to optimize performance. This may involve identifying and resolving performance bottlenecks or adding additional hardware resources.
- Security Management: The DBA must ensure that the database is secured against unauthorized access. They must manage user accounts and permissions, implement security protocols, and monitor the system for any security breaches.
- Data Migration: The DBA must be able to move data between different database systems, including migrating data from legacy systems to newer ones.
- Troubleshooting: The DBA must be able to identify and resolve issues with the database system. This may involve identifying and fixing bugs in the database software, resolving performance issues, or restoring data from backups.
The responsibilities of DBA are as follows −
- Makes the decision concerning the content of the database.
- Plans the storage structure and access strategy.
- Provides the support to the users.
- Defines the security and integrity checks.
- Interpreter backup and recovery strategies.
- Monitoring the performance and responding to the changes in the requirements.
(c) Differentiate strong entity set and weak entity set. Demonstrate the concept of both using real-time example using E-R diagram.
| Strong Entity | Weak Entity |
|---|---|
| Strong entity always has a primary key. | While a weak entity has a partial discriminator key. |
| Strong entity is not dependent on any other entity. | Weak entity depends on strong entity. |
| Strong entity is represented by a single rectangle. | Weak entity is represented by a double rectangle. |
| Two strong entity’s relationship is represented by a single diamond. | While the relation between one strong and one weak entity is represented by a double diamond. |
| Strong entities have either total participation or not. | While weak entity always has total participation. |
- Strong Entity:
A strong entity is not dependent on any other entity in the schema. A strong entity will always have a primary key. Strong entities are represented by a single rectangle. The relationship of two strong entities is represented by a single diamond.
Various strong entities, when combined together, create a strong entity set.
- Weak Entity:
A weak entity is dependent on a strong entity to ensure its existence. Unlike a strong entity, a weak entity does not have any primary key. It instead has a partial discriminator key. A weak entity is represented by a double rectangle.
The relation between one strong and one weak entity is represented by a double diamond. This relationship is also known as identifying relationship.
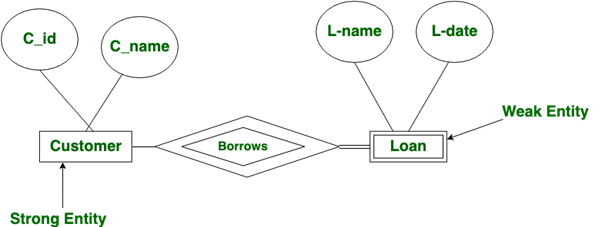
Here Customer is Strong entity and Loan is weak entity.
(a)Consider the relation scheme R = {E, F, G, H, I, J, K, L, M, M} and the set of functional dependencies {{E, F} -> {G}, {F} -> {I, J}, {E, H} -> {K, L}, K -> {M}, L -> {N} on R. What is the key for R ?
We know that K is a key for Relation schema R it K → R; i.e. K functionally determines each & every attribute of R. This is definition off key using functional dependency.
Now, the Given Relation-Schema is R (E, F, G, H, I, J, K, L, M, N) and the Given functional dependencies :
{E, F} → {G} (i) {K} → {M} (iv)
{F} → {I, J} (ii) {L} → {N} (v)
{E, H} → {K, L} (iii)
Now we need to find function dependency whose right side is R.
(a) {E, F} Cannot be a key as it determines only ‘G’
(b) {E, F, H} is a key:
⚈ using Transitivity on (i) and (ii) we get
{E, F} → {G, I, J} …….(vi) ·
⚈ using preudotransitivity on (iii) and (vi) we get
{E, F, H} → {G, I, J, K, L} ……..(vii)
⚈ using Decomposition on (vii) we get
{E, F, H} → {K} and {E, F, H} → {L}
Combining above with (iv) and (v) respectively
{E, F, H} → {M} and {E, F, H} → {N}
Now, finally performing union of these with (vii) we get:
{E, F, H} → {G, I, J, K, L, M, N} ………..(viii)
Also {E, F, H} → {E, F, H} is trivial, combine this with (viii) using union, we get:
{E, F, H} → {E, F, G, H, I, J, K, L, M, N}
⇒ {E, F, H} → R
So, {E, F, H} is a key of R.
(b) Consider a relation scheme R = (A, B, C, D, E, H) on which the following functional dependencies hold: {A–>B, BC–> D, E–>C, D–>A}. What are the candidate keys of R?( Any 1 in case of more than one candidate key
A → B, BC → D, E → C, D → A
We start form set of all the attributes and reduce them using given functional dependences
ABCDEH ABCDEH
ABCEH {BC- → D}
ABEH{E → C} BCDEH {D → A}
AEH {A → B} BEH {E → C}
ABCDEH ACDEH {A → B} ADEH{E → C} DEH{D → A}
So candidate keys are AEH, BEH & DEH .
(c) Draw an E-R diagram of following scenario. Make necessary assumptions and clearly note down the same.We would like to make our College’s manually operated Library to fully computerized.
The Library Management System database keeps track of readers with the following considerations –
- The system keeps track of the staff with a single point authentication system comprising login Id and password.
- Staff maintains the book catalog with its ISBN, Book title, price(in INR), category(novel, general, story), edition, author Number and details.
- A publisher has publisher Id, Year when the book was published, and name of the book.
- Readers are registered with their user_id, email, name (first name, last name), Phone no (multiple entries allowed), communication address. The staff keeps track of readers.
- Readers can return/reserve books that stamps with issue date and return date. If not returned within the prescribed time period, it may have a due date too.
- Staff also generate reports that has readers id, registration no of report, book no and return/issue info.
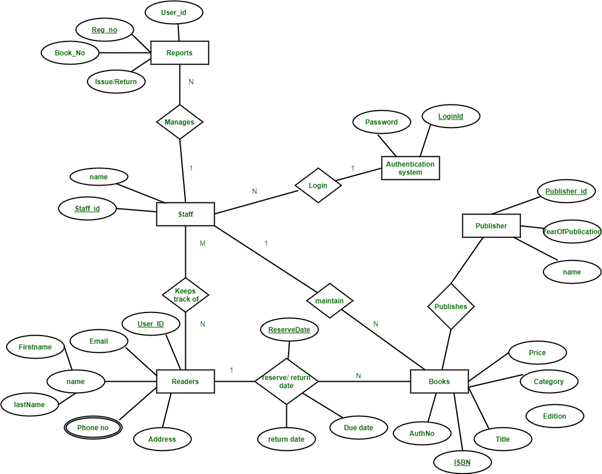
This Library ER diagram illustrates key information about the Library, including entities such as staff, readers, books, publishers, reports, and authentication system. It allows for understanding the relationships between entities.
Entities and their Attributes :
- Book Entity : It has authno, isbn number, title, edition, category, price. ISBN is the Primary Key for Book Entity.
- Reader Entity : It has UserId, Email, address, phone no, name. Name is composite attribute of firstname and lastname. Phone no is multi valued attribute. UserId is the Primary Key for Readers entity.
- Publisher Entity : It has PublisherId, Year of publication, name. PublisherID is the Primary Key.
- Authentication System Entity : It has LoginId and password with LoginID as Primary Key.
- Reports Entity : It has UserId, Reg_no, Book_no, Issue/Return date. Reg_no is the Primary Key of reports entity.
- Staff Entity : It has name and staff_id with staff_id as Primary Key.
- Reserve/Return Relationship Set : It has three attributes: Reserve date, Due date, Return date.
Relationships between Entities –
- A reader can reserve N books but one book can be reserved by only one reader. The relationship 1:N.
- A publisher can publish many books but a book is published by only one publisher. The relationship 1:N.
- Staff keeps track of readers. The relationship is M:N.
- Staff maintains multiple reports. The relationship 1:N.
- Staff maintains multiple Books. The relationship 1:N.
- Authentication system provides login to multiple staffs. The relation is 1:N.
(a) Define the terms: a) Primary Key b) Super Key
Primary Key:
A Primary Key is the minimal set of attributes of a table that has the task to uniquely identify the rows, or we can say the tuples of the given particular table.A primary key of a relation is one of the possible candidate keys which the database designer thinks it’s primary. It may be selected for convenience, performance and many other reasons.
Super Key :
We can define a super key as a set of those keys that identify a row or a tuple uniquely. The word super denotes the superiority of a key. Thus, a super key is the superset of a key known as a Candidate key. It means a candidate key is obtained from a super key only.
(b) List the type of joins in relational algebra. Explain with example.
There are five types of Join
- Inner Join
- Left Join
- Right Join
- Full Join
- Cartesial Join
Example: Let’s say we have two tables: Customers and Orders.
Customers table:
| CustomerID | Name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
Orders table:
| OrderID | CustomerID | Amount |
|---|---|---|
| 100 | 1 | 20 |
| 101 | 2 | 30 |
| 102 | 1 | 10 |
Inner Join on CustomerID:
| CustomerID | Name | OrderID | Amount |
|---|---|---|---|
| 1 | Alice | 100 | 20 |
| 1 | Alice | 102 | 10 |
| 2 | Bob | 101 | 30 |
Left Join on CustomerID:
| CustomerID | Name | OrderID | Amount |
|---|---|---|---|
| 1 | Alice | 100 | 20 |
| 1 | Alice | 102 | 10 |
| 2 | Bob | 101 | 30 |
| 3 | Carol | NULL | NULL |
Right Join on CustomerID:
| CustomerID | Name | OrderID | Amount |
|---|---|---|---|
| 1 | Alice | 100 | 20 |
| 1 | Alice | 102 | 10 |
| 2 | Bob | 101 | 30 |
Full Join on CustomerID:
| CustomerID | Name | OrderID | Amount |
|---|---|---|---|
| 1 | Alice | 100 | 20 |
| 1 | Alice | 102 | 10 |
| 2 | Bob | 101 | 30 |
(c) Which operator is used for “For All “type of queries? Explain same with example.
The “For All” operator in relational algebra is represented by the universal quantifier symbol “∀”.
It is used to filter the rows from a table based on a condition that applies to all rows in the table.
For example, if we have a “Customers” table and we want to find all customers who have placed an order for an amount greater than $50, we can use the following relational algebra expression:
∀ (Customers ⋈ Orders.CustomerID = Customers.CustomerID) (Orders.Amount > 50)
This expression means “For all customers, select the customers whose order amount is greater than 50 dollars”
In this example, the “Customers” table is joined with the “Orders” table on the “CustomerID” field. The condition “Orders.Amount > 50” is applied to all rows of the joined table, and only the rows that satisfy the condition are returned.
Note that this operator can also be represented with the keyword “SELECT*” Example: SELECT * FROM Customers WHERE NOT EXISTS (SELECT 1 FROM Orders WHERE Orders.Amount <= 50 and Orders.CustomerID = Customers.CustomerID)
This SQL query returns the same result as the previous example, but using SQL syntax instead of relational algebra.
(a) Define the terms : a) foreign key b) candidate key
Foreign Key:
A foreign key is the one that is used to link two tables together via the primary key. It means the columns of one table points to the primary key attribute of the other table. It further means that if any attribute is set as a primary key attribute will work in another table as a foreign key attribute. But one should know that a foreign key has nothing to do with the primary key.
Candidate Key
A candidate key is a subset of a super key set where the key which contains no redundant attribute is none other than a Candidate Key. In order to select the candidate keys from the set of super key, we need to look at the super key set.
(b) List unary relational operators and explain with example.
In relational algebra, unary operators are operators that operate on a single relation (table). The following are some common unary operators:
Projection: The projection operator is represented by the symbol π and is used to select specific columns from a table. For example, if we have a “Customers” table with columns “CustomerID”, “Name”, “Address”, “Phone”, we can use the following relational algebra expression to select only the “Name” and “Address” columns: πName, Address (Customers)
Selection: The selection operator is represented by the symbol σ and is used to filter rows from a table based on a condition. For example, if we have a “Customers” table and we want to find all customers who live in a specific city, we can use the following relational algebra expression: σCity = ‘New York’ (Customers)
Rename: The rename operator is represented by the symbol ρ and is used to change the name of a relation. For example, if we have a “Customers” table and we want to change the name to “Clients”, we can use the following relational algebra expression: ρClients (Customers)
Difference: The difference operator is represented by the symbol – and is used to find the difference between two relations. For example, if we have two tables “Customers” and “Clients” and want to find the customers that are not clients, we can use the following relational algebra expression: Customers – Clients
Union: The union operator is represented by the symbol ∪ and is used to combine the rows from two relations. For example, if we have two tables “Customers” and “Clients” and want to find all the customers and clients, we can use the following relational algebra expression: Customers ∪ Clients
Intersection: The intersection operator is represented by the symbol ∩ and is used to find the common rows between two relations. For example, if we have two tables “Customers” and “Clients” and want to find the customers that are also clients, we can use the following relational algebra expression: Customers ∩ Clients
(c) Consider the following relational database schema consisting of the four relation schemas:
passenger ( pid, pname, pgender, pcity)
agency ( aid, aname, acity)
flight (fid, fdate, time, src, dest)
booking (pid, aid, fid, fdate)
Answer the following questions using relational algebra queries.
a. Get the details about all flights from Chennai to New Delhi.
b. Get the complete details of all flights to New Delhi.
c. Find the passenger names for passengers who have bookings on at least one flight.
a. Get the details about all flights from Chennai to New Delhi.
σ src = “Chennai” ^ dest = “New Delhi” (flight)b. Get the complete details of all flights to New Delhi.
σ destination = “New Delhi” (flight)c. Find the passenger names for passengers who have bookings on at least one flight.
Πpname (passenger ⨝ booking)(a) List and explain ACID properties with respect to Database transaction.
ACID properties are a set of properties that are used to ensure the reliability and consistency of database transactions. The properties are as follows:
- Atomicity: Atomicity means that a transaction is treated as a single, indivisible unit of work. This means that either all the operations in a transaction are completed successfully, or none of them are completed. If any operation in a transaction fails, the entire transaction is rolled back to its original state.
For example, consider a bank transfer transaction that involves debiting the account of one customer and crediting the account of another customer. If the debit operation is successful but the credit operation fails, the entire transaction will be rolled back, and the account of the first customer will not be debited.
- Consistency: Consistency means that a transaction brings the database from one valid state to another. The database must satisfy certain integrity constraints before and after the transaction. If the constraints are violated, the transaction is rolled back.
For example, consider a transaction that transfers money between two accounts. The transaction should maintain the total balance of all the accounts involved in the transaction.
- Isolation: Isolation means that multiple transactions can occur concurrently without affecting each other. Each transaction must be executed as if it were the only transaction in the system. This means that the intermediate states of a transaction should be invisible to other transactions.
For example, consider two transactions that access the same bank account. The isolation property ensures that the two transactions are executed independently, and the results of one transaction are not visible to the other transaction until it is committed.
- Durability: Durability means that once a transaction is committed, its effects are permanent and will survive subsequent system failures. The changes made to the database by a committed transaction should be stored permanently in non-volatile memory.
For example, consider a database that is updated with a new record. The durability property ensures that the new record will not be lost due to a system failure.
In summary, the ACID properties ensure that database transactions are reliable, consistent, and durable. They are important for ensuring the integrity of data in a database and are widely used in modern database management systems.
(b) Explain RAID Levels with respect to Data Storage.
RAID (Redundant Array of Independent Disks) is a technology used for data storage that combines multiple physical hard drives into a single logical unit. RAID levels define the specific ways in which the data is distributed and protected across these physical disks. There are several RAID levels, each with its own set of advantages and disadvantages. Here are some of the most common RAID levels:
- RAID 0: This level provides no redundancy but offers increased performance by spreading data across multiple disks. It works by dividing data into small segments and writing them to different disks in parallel. However, if one disk fails, the entire array fails, and data may be lost.
- RAID 1: This level provides complete redundancy by mirroring data across two or more disks. Each disk contains an identical copy of the data, so if one disk fails, the other(s) can continue to function. This level provides high data reliability but requires more disks than RAID 0.
- RAID 5: This level provides both performance and redundancy. It stripes data across multiple disks and also generates parity data, which is used to reconstruct lost data if one disk fails. It requires at least three disks, and performance decreases as the number of disks increases.
- RAID 6: This level is similar to RAID 5 but uses two sets of parity data, providing even greater fault tolerance. It can tolerate the failure of two disks without losing any data. However, it requires more disks than RAID 5.
- RAID 10: This level combines the benefits of RAID 0 and RAID 1. It uses four or more disks and mirrors two RAID 0 arrays. It provides high performance and complete redundancy but requires more disks than other RAID levels.
The choice of RAID level depends on the specific needs of the application, such as performance, data reliability, and cost.
(c) Explain the concept of Conflict Serializable with suitable schedules
A schedule is called conflict serializability if after swapping of non-conflicting operations, it can transform into a serial schedule.
The schedule will be a conflict serializable if it is conflict equivalent to a serial schedule.
- Conflicting Operations
The two operations become conflicting if all conditions satisfy:
- Both belong to separate transactions.
- They have the same data item.
- They contain at least one write operation.
Example:
Swapping is possible only if S1 and S2 are logically equal.
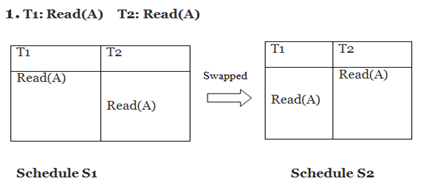
Here, S1 = S2. That means it is non-conflict.
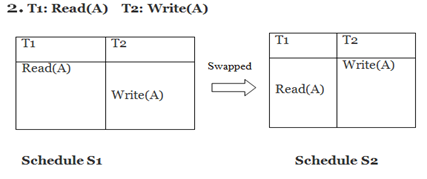
Here, S1 ≠ S2. That means it is conflict.
In the conflict equivalent, one can be transformed to another by swapping non-conflicting operations. In the given example, S2 is conflict equivalent to S1 (S1 can be converted to S2by swapping non-conflicting operations).
Two schedules are said to be conflict equivalent if and only if:
- They contain the same set of the transaction.
- If each pair of conflict operations are ordered in the same way.
- Example:
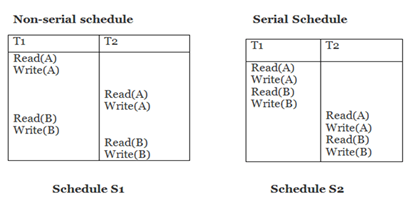
Schedule S2 is a serial schedule because, in this, all operations of T1 are performed before starting any operation of T2. Schedule S1 can be transformed into a serial schedule by swapping non-conflicting operations of S1.
After swapping of non-conflict operations, the schedule S1 becomes:
| T1 | T2 |
| Read(A) Write(A) Read(B) Write(B) | |
| Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
(a) List and explain types of locks in transactions.
There are two types of Locks
- Shared lock
- Exclusive lock
1. Shared Lock (S):
- Another transaction that tries to read the same data is permitted to read, but a transaction that tries to update the data will be prevented from doing so until the shared lock is released.
- Shared lock is also called read lock, used for reading data items only.
- Shared locks support read integrity. They ensure that a record is not in process of being updated during a read-only request.
- Shared locks can also be used to prevent any kind of updates of record.
- It is denoted by Lock-S.
- S-lock is requested using Lock-S instruction.
For example, consider a case where initially A=100 and there are two transactions which are reading A. If one of transaction wants to update A, in that case other transaction would be reading wrong value. However, Shared lock prevents it from updating until it has finished reading.
2. Exclusive Lock (X) :
- When a statement modifies data, its transaction holds an exclusive lock on data that prevents other transactions from accessing the data.
- This lock remains in place until the transaction holding the lock issues a commit or rollback.
- They can be owned by only one transaction at a time.
- With the Exclusive Lock, a data item can be read as well as written. Also called write lock.
- Any transaction that requires an exclusive lock must wait if another transaction currently owns an exclusive lock or a shared lock against the requested resource.
- They can be owned by only one transaction at a time.
- It is denoted as Lock-X.
- X-lock is requested using Lock-X instruction.
For example, consider a case where initially A=100 when a transaction needs to deduct 50 from A. We can allow this transaction by placing X lock on it. Therefore, when the any other transaction wants to read or write, exclusive lock prevent it.
(b) With neat diagram explain data storage hierarchy so far.
The data storage hierarchy is a concept that explains how data is stored in a computer system from the lowest level to the highest level. The hierarchy starts with the smallest unit of storage and goes up to the largest unit of storage. The hierarchy is usually represented as a pyramid with the smallest storage unit at the top and the largest unit at the bottom.
The different levels of the data storage hierarchy are as follows:
- Registers: Registers are the smallest and fastest form of storage used by the computer. They are located in the CPU and are used to hold data that is currently being processed. Registers are very expensive to produce and are usually used in small quantities.
- Cache Memory: Cache memory is the next level of storage in the hierarchy. It is located between the CPU and the main memory. Cache memory is used to store frequently accessed data to reduce the time required to access data from the main memory. It is faster than main memory but smaller in size.
- Main Memory: Main memory is also known as Random Access Memory (RAM). It is used to store data and program instructions that are currently being used by the computer. Main memory is faster than secondary storage but more expensive.
- Secondary Storage: Secondary storage is used to store data and program files that are not currently being used by the computer. It includes hard disk drives, solid-state drives, and optical drives. Secondary storage is slower than main memory but cheaper.
- Tertiary Storage: Tertiary storage is used for long-term archival storage. It includes tape drives, optical jukeboxes, and other mass storage devices. Tertiary storage is slower than secondary storage but cheaper.
(c) Explain deadlock with suitable scheduling examples.
A Deadlock is a condition where two or more transactions are waiting indefinitely for one another to give up locks.
Deadlock is said to be one of the most feared complications in DBMS as no task ever gets finished and is in waiting state forever.
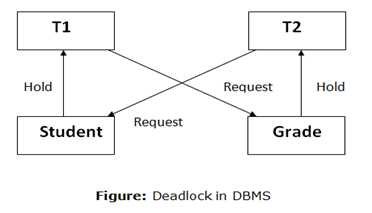
For example: In the student table, transaction T1 holds a lock on some rows and needs to update some rows in the grade table. Simultaneously, transaction T2 holds locks on some rows in the grade table and needs to update the rows in the Student table held by Transaction T1.
Now, the main problem arises. Now Transaction T1 is waiting for T2 to release its lock and similarly, transaction T2 is waiting for T1 to release its lock. All activities come to a halt state and remain at a standstill. It will remain in a standstill until the DBMS detects the deadlock and aborts one of the transactions.
This condition is called Deadlock condition.
(a) Explain following SQL commands with syntax and significance. Grant & Revoke
- Grant :
SQL Grant command is specifically used to provide privileges to database objects for a user. This command also allows users to grant permissions to other users too.
Syntax:
grant privilege_name on object_name
to {user_name | public | role_name}
Here privilege_name is which permission has to be granted, object_name is the name of the database object, user_name is the user to which access should be provided, the public is used to permit access to all the users.
- Revoke :
Revoke command withdraw user privileges on database objects if any granted. It does operations opposite to the Grant command. When a privilege is revoked from a particular user U, then the privileges granted to all other users by user U will be revoked.
Syntax:
revoke privilege_name on object_name
from {user_name | public | role_name}
(b)
TABLE Worker(WORKER_ID INT NOT NULL PRIMARY KEY,FIRST_NAME CHAR(25), LAST_NAME CHAR(25),SALARY INT(15),JOINING_DATE DATETIME,DEPARTMENT CHAR(25));
TABLE Bonus(WORKER_REF_ID INT,BONUS_AMOUNT INT(10),BONUS_DATE DATETIME,FOREIGN KEY (WORKER_REF_ID),REFERENCES Worker(WORKER_ID));
TABLE Title(WORKER_REF_ID INT,WORKER_TITLE CHAR(25),AFFECTED_FROM DATETIME,FOREIGN KEY (WORKER_REF_ID)REFERENCES Worker(WORKER_ID));
Consider above 3 tables ,assume appropriate data and solve following SQL queries
1. Find out unique values of DEPARTMENT from Worker table
2. Print details of the Workers whose SALARY lies between 100000 and 500000.
3. Print details of the Workers who have joined in Feb’2014.
4. Fetch worker names with salaries >= 50000 and <= 100000.
- Find out unique values of DEPARTMENT from Worker table
Select distinct DEPARTMENT from Worker;- Print details of the Workers whose SALARY lies between 100000 and 500000.
Select * from Worker where SALARY between 100000 and 500000;- Print details of the Workers who have joined in Feb’2014.
Select * from Worker where year(JOINING_DATE) = 2014 and month(JOINING_DATE) = 2;- Fetch worker names with salaries >= 50000 and <= 100000.
SELECT CONCAT(FIRST_NAME, ' ', LAST_NAME) As Worker_Name, Salary
FROM worker
WHERE WORKER_ID IN
(SELECT WORKER_ID FROM worker
WHERE Salary BETWEEN 5000 AND 10000);(c) Write short note on query processing.
Query Processing is the activity performed in extracting data from the database. In query processing, it takes various steps for fetching the data from the database. The steps involved are:
- Parsing and translation
- Optimization
- Evaluation
The query processing works in the following way:
Parsing and Translation
As query processing includes certain activities for data retrieval. Initially, the given user queries get translated in high-level database languages such as SQL. It gets translated into expressions that can be further used at the physical level of the file system. After this, the actual evaluation of the queries and a variety of query -optimizing transformations and takes place. Thus before processing a query, a computer system needs to translate the query into a human-readable and understandable language. Consequently, SQL or Structured Query Language is the best suitable choice for humans. But, it is not perfectly suitable for the internal representation of the query to the system. Relational algebra is well suited for the internal representation of a query. The translation process in query processing is similar to the parser of a query. When a user executes any query, for generating the internal form of the query, the parser in the system checks the syntax of the query, verifies the name of the relation in the database, the tuple, and finally the required attribute value. The parser creates a tree of the query, known as ‘parse-tree.’ Further, translate it into the form of relational algebra. With this, it evenly replaces all the use of the views when used in the query.
Thus, we can understand the working of a query processing in the below-described diagram:Play Video
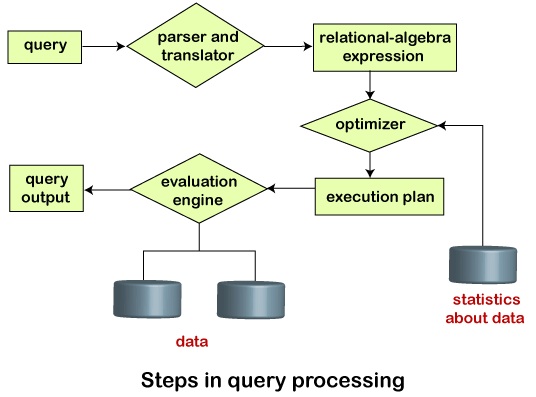
Suppose a user executes a query. As we have learned that there are various methods of extracting the data from the database. In SQL, a user wants to fetch the records of the employees whose salary is greater than or equal to 10000. For doing this, the following query is undertaken:
select emp_name from Employee where salary>10000;
Thus, to make the system understand the user query, it needs to be translated in the form of relational algebra. We can bring this query in the relational algebra form as:
- σsalary>10000 (πsalary (Employee))
- πsalary (σsalary>10000 (Employee))
After translating the given query, we can execute each relational algebra operation by using different algorithms. So, in this way, a query processing begins its working.
Evaluation
For this, with addition to the relational algebra translation, it is required to annotate the translated relational algebra expression with the instructions used for specifying and evaluating each operation. Thus, after translating the user query, the system executes a query evaluation plan.
Query Evaluation Plan
- In order to fully evaluate a query, the system needs to construct a query evaluation plan.
- The annotations in the evaluation plan may refer to the algorithms to be used for the particular index or the specific operations.
- Such relational algebra with annotations is referred to as Evaluation Primitives. The evaluation primitives carry the instructions needed for the evaluation of the operation.
- Thus, a query evaluation plan defines a sequence of primitive operations used for evaluating a query. The query evaluation plan is also referred to as the query execution plan.
- A query execution engine is responsible for generating the output of the given query. It takes the query execution plan, executes it, and finally makes the output for the user query.
Optimization
- The cost of the query evaluation can vary for different types of queries. Although the system is responsible for constructing the evaluation plan, the user does need not to write their query efficiently.
- Usually, a database system generates an efficient query evaluation plan, which minimizes its cost. This type of task performed by the database system and is known as Query Optimization.
- For optimizing a query, the query optimizer should have an estimated cost analysis of each operation. It is because the overall operation cost depends on the memory allocations to several operations, execution costs, and so on.
Finally, after selecting an evaluation plan, the system evaluates the query and produces the output of the query.
(a) Explain following SQL commands with syntax and significance. Commit & Rollback.
1. COMMIT:
COMMIT in SQL is a transaction control language that is used to permanently save the changes done in the transaction in tables/databases. The database cannot regain its previous state after its execution of commit.
Example: Consider the following STAFF table with records:
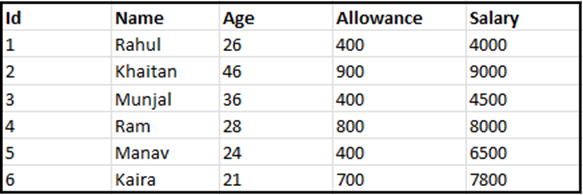
sql> SELECT * FROM Staff WHERE Allowance = 400; sql> COMMIT;
Output:

So, the SELECT statement produced the output consisting of three rows.
2. ROLLBACK:
ROLLBACK in SQL is a transactional control language that is used to undo the transactions that have not been saved in the database. The command is only been used to undo changes since the last COMMIT.
Example: Consider the following STAFF table with records:
STAFF
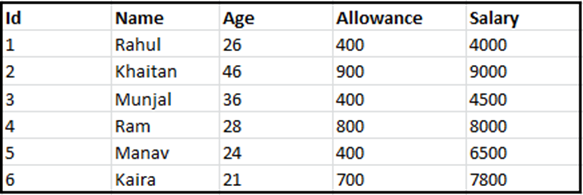
sql> SELECT * FROM EMPLOYEES WHERE ALLOWANCE = 400; sql> ROLLBACK;
Output:
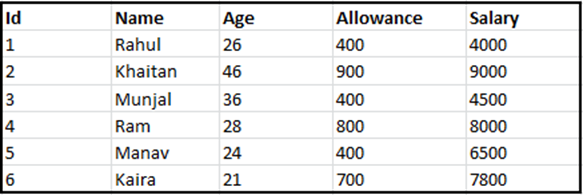
So, the SELECT statement produced the same output with the ROLLBACK command.
(b) TABLE Worker(WORKER_ID INT NOT NULL PRIMARY KEY,FIRST_NAME CHAR(25), LAST_NAME CHAR(25),SALARY INT(15),JOINING_DATE DATETIME,DEPARTMENT CHAR(25));
TABLE Bonus(WORKER_REF_ID INT,BONUS_AMOUNT INT(10),BONUS_DATE DATETIME,FOREIGN KEY (WORKER_REF_ID),REFERENCES Worker(WORKER_ID));
TABLE Title(WORKER_REF_ID INT,WORKER_TITLE CHAR(25), AFFECTED_FROM DATETIME,FOREIGN KEY (WORKER_REF_ID)REFERENCES Worker(WORKER_ID));
Consider above 3 tables ,assume appropriate data and solve following SQL queries
1. Print details of the Workers who are also Managers.
2. SQL query to clone a new table from another table.
3. Fetch the list of employees with the same salary.
4. Fetch “FIRST_NAME” from Worker table in upper case.
- Print details of the Workers who are also Managers.
SELECT DISTINCT W.FIRST_NAME, T.WORKER_TITLE
FROM Worker W
INNER JOIN Title T
ON W.WORKER_ID = T.WORKER_REF_ID
AND T.WORKER_TITLE in ('Manager');- SQL query to clone a new table from another table.
SELECT * INTO WorkerClone FROM Worker;- Fetch the list of employees with the same salary.
Select distinct W.WORKER_ID, W.FIRST_NAME, W.Salary
from Worker W, Worker W1
where W.Salary = W1.Salary
and W.WORKER_ID != W1.WORKER_ID;- Fetch “FIRST_NAME” from Worker table in upper case.
Select upper(FIRST_NAME) from Worker;(c) List the techniques to obtain the query cost. Explain any one.
The expense assessment of a query assessment plan is determined by keeping in mind the different assets that follow as:
- The number of disk accesses.
- Time of Execution taken by the CPU to execute a query.
- The involved Communication costs in either distributed or parallel database systems.
To estimate the cost of a query evaluation plan, we use the number of blocks transferred from the disk, and the number of disks seeks.
Suppose the disk has an average block access time of ts seconds and takes an average of tT seconds to transfer x data blocks.
The block access time is the sum of disk seeks time and rotational latency. It performs S seeks than the time taken will be b*tT + S*tS seconds. If tT=0.1 ms, tS =4 ms, the block size is 4 KB, and its transfer rate is 40 MB per second. With this, we can easily calculate the estimated cost of the given query evaluation plan.
Generally, for estimating the cost, we consider the worst case that could happen. The users assume that initially, the data is read from the disk only. But there must be a chance that the information is already present in the main memory. However, the users usually ignore this effect, and due to this, the actual cost of execution comes out less than the estimated value.
The response time, i.e., the time required to execute the plan, could be used for estimating the cost of the query evaluation plan. But due to the following reasons, it becomes difficult to calculate the response time without actually executing the query evaluation plan:
- When the query begins its execution, the response time becomes dependent on the contents stored in the buffer. But this information is difficult to retrieve when the query is in optimized mode, or it is not available also.
- When a system with multiple disks is present, the response time depends on an interrogation that in “what way accesses are distributed among the disks?”. It is difficult to estimate without having detailed knowledge of the data layout present over the disk.
- Consequently, instead of minimizing the response time for any query evaluation plan, the optimizers finds it better to reduce the total resource consumption of the query plan. Thus to estimate the cost of a query evaluation plan, it is good to minimize the resources used for accessing the disk or use of the extra resources.
Read More : DBMS GTU Paper Solution Winter 2021
Read More : DF GTU Paper Solution Winter 2021
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.