Here, We provide Computer Organization & Architecture GTU Paper Solution Winter 2022. Read the Full COA GTU paper solution given below.
Computer Organization & Architecture GTU Old Paper Winter 2022 [Marks: 70] : Click Here
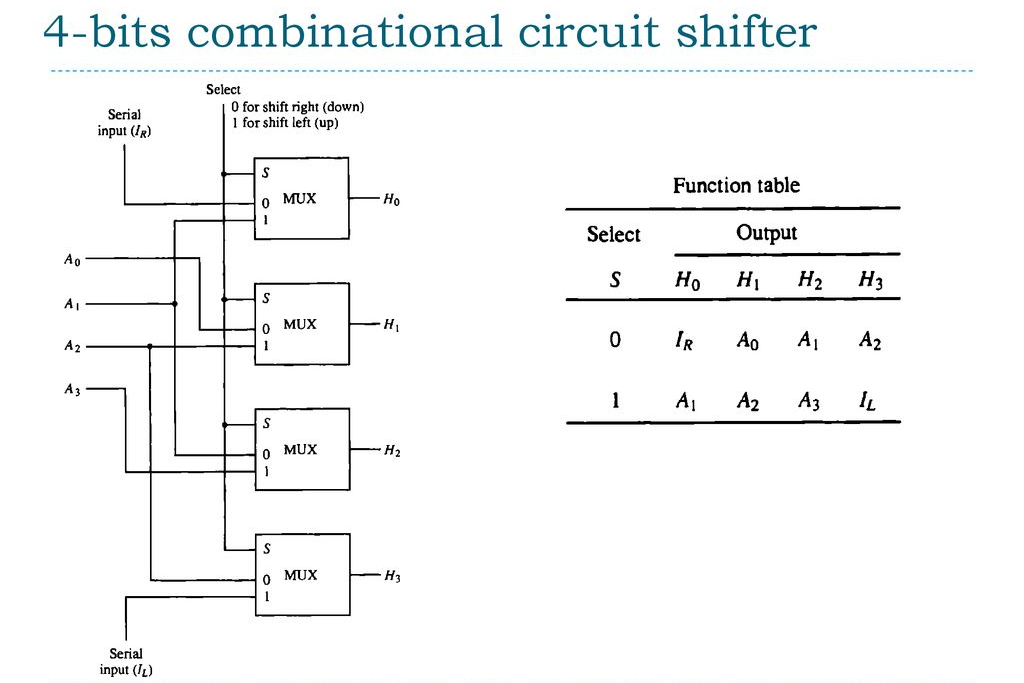
(a) Draw the block diagram of 4-bit combinational circuit shifter.
Here is the block diagram of a 4-bit combinational circuit shifter:
_________ _________ _________ _________
| | | | | | | |
[3..0] --> | SHIFT | -->| SHIFT | -->| SHIFT | -->| SHIFT | --> [3..0]
| LEFT | | UP | | RIGHT | | DOWN |
[DIR] --> |_________| |_________| |_________| |_________|
The circuit takes a 4-bit input [3..0] and a direction signal [DIR], and outputs the shifted 4-bit result. The direction signal can take four possible values: LEFT, UP, RIGHT, or DOWN, which correspond to shifting the input to the left, up (towards the most significant bit), right, or down (towards the least significant bit), respectively.
The circuit consists of four identical shift blocks, each of which shifts the input one bit in the specified direction. The output of each block is connected to the input of the next block in the sequence. The direction signal is used to control the operation of the shift blocks.
(b) Construct diagram of common bus system of four 4-bits registers with
diagram.
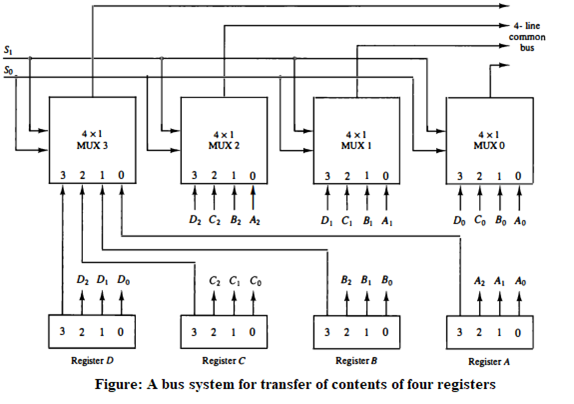
In this system, four 4-bit registers (A, B, C, and D) share a common bus. The bus allows each register to communicate with other registers and external devices. Each register has an input and output port connected to the bus. When a register needs to read or write data, it sends a request to the bus controller, which then grants access to the bus. The bus controller also ensures that only one register can write to the bus at a time to avoid data collisions.
(c) What is the role of sequence counter(SC) in control unit? Interpret its
concept with the help of its three inputs using diagram.
In a digital circuit, the sequence counter (SC) is a type of counter that is used to generate a sequence of states. The role of the sequence counter in the control unit is to generate control signals for various operations based on the state of the system.
The sequence counter has three inputs: clock input (CLK), clear input (CLR), and enable input (EN). The CLK input provides the clock signal to the counter, which is used to synchronize the counter with other parts of the system. The CLR input resets the counter to its initial state, and the EN input enables the counter to count.
The diagram of a sequence counter with its inputs is shown below:
+-----+
CLK -->| |
| SC |
CLR -->| |
| |
EN -->| |
+-----+
The sequence counter can be used to generate a sequence of states that can be used to control various operations in the system. For example, the sequence counter can be used to generate a sequence of addresses for accessing memory locations or for executing a series of instructions.
(a) List out names of eight main registers of basic computer with their
symbolic name and purpose.
Here are the eight main registers of a basic computer with their symbolic name and purpose:
- Accumulator (AC): It is used to store intermediate results of arithmetic and logical operations.
- Program Counter (PC): It holds the memory address of the next instruction to be executed.
- Memory Address Register (MAR): It holds the memory address of the data to be fetched or stored.
- Memory Buffer Register (MBR): It holds the data to be written to or read from memory.
- Instruction Register (IR): It holds the current instruction being executed.
- Index Register (X): It is used as a pointer to memory locations and is often used for indexing arrays.
- Stack Pointer (SP): It is used to keep track of the top of the stack in memory.
- Status Register (SR): It contains flags that indicate the outcome of the most recent arithmetic or logical operation.
(b) Summarize following addressing modes with example.
1) Implied mode 2) Register mode
- Implied Mode: In this addressing mode, the operand is implicitly understood and no specific instruction is needed to specify it. The operand is already known or implied by the instruction itself. This mode is commonly used for instructions that do not require an operand, such as branch or jump instructions. For example, the instruction “BRZ” (branch if zero) in a computer’s assembly language implies that the operand is the current program counter (PC) value, and the instruction jumps to the specified location if the accumulator is zero.
- Register Mode: In this addressing mode, the operand is stored in a register, and the instruction specifies which register to use. The register is either explicitly named in the instruction or is implied by the opcode. For example, the instruction “ADD R1, R2” adds the contents of register R2 to register R1 and stores the result in R1. In this case, the operand is in register R2, and the instruction specifies the destination register R1. This mode is commonly used for arithmetic and logical operations.
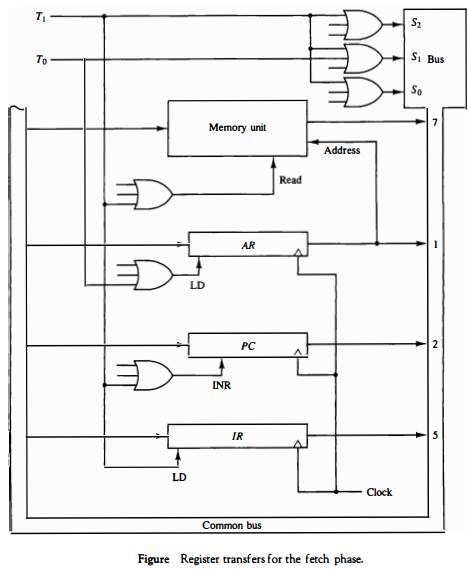
(c) Which are the different phases of Instruction Cycle? Describe Register
transfer for fetch phase with its diagram.
The different phases of the Instruction Cycle are:
- Fetch: The fetch phase is the first phase in the instruction cycle. In this phase, the instruction is fetched from memory and loaded into the instruction register (IR).
- Decode: In the decode phase, the instruction in the IR is decoded and the necessary operations are identified.
- Execute: In the execute phase, the operation specified by the instruction is performed.
- Store: In the store phase, the result of the operation is stored back in memory or in a register.
Register Transfer for Fetch Phase:
During the fetch phase, the control unit performs the following register transfer operations:
- The program counter (PC) is loaded with the address of the next instruction to be fetched.
- The contents of the PC are transferred to the memory address register (MAR).
- The control unit sends a read signal to memory, and the contents of the memory location specified by the MAR are loaded into the memory data register (MDR).
- The contents of the MDR are transferred to the instruction register (IR).
The diagram of register transfer for fetch phase is as follows:
(c) Define: microinstruction; Identify different types of 16 bits instruction
formats for basic computer using figure.
A microinstruction is a low-level instruction used by a microprogrammed control unit to perform operations in a computer’s central processing unit (CPU).
There are four different types of 16-bit instruction formats for a basic computer:
- Register-reference instructions: These instructions specify a register as an operand and reference it in the operation. Example: ADD A, R1
- Immediate instructions: These instructions specify an immediate data value as an operand. Example: MOV A, #5
- Direct instructions: These instructions specify a memory address as an operand. Example: MOV A, 2000H
- Indirect instructions: These instructions specify a register that contains a memory address as an operand. Example: MOV A, (R1)
(a) Use BSA and BUN instruction with example and diagram.
BSA (Branch and Save Return Address) and BUN (Branch Unconditionally) are two types of instructions used in computer programming to change the flow of program execution.
BSA Instruction: The BSA instruction is used to call a subroutine in a program. It saves the current value of the program counter (the address of the next instruction to be executed) in a register called the Link Register and transfers control to the address specified in the instruction. The Link Register is used to return control to the instruction following the BSA instruction after the subroutine is executed.
BUN Instruction: The BUN instruction is used to transfer control to a new address unconditionally. It simply sets the program counter to the address specified in the instruction and continues execution from there.

(b) Criticize Three-Address Instructions and Zero address instruction with
common example.
Three-Address Instructions and Zero Address Instructions are two different types of instruction formats used in computers. Here are some criticisms of each:
Criticisms of Three-Address Instructions:
- They require more memory space to store than other instruction formats, such as one-address or zero-address instructions.
- They can be more complex to decode and execute than other instruction formats.
- They can lead to longer execution times for certain operations that require multiple operands, such as multiplication or division.
Example of Three-Address Instruction: ADD R1, R2, R3 (Adds the values in registers R2 and R3 and stores the result in R1.)
Criticisms of Zero-Address Instructions:
- They can be less flexible than other instruction formats because they only allow operations on the top of the stack.
- They can be slower to execute than other instruction formats because they require more memory access operations to retrieve operands from the stack.
Example of Zero-Address Instruction: POP (Pops the top value from the stack and stores it in a register.)
Overall, the choice of instruction format depends on the specific needs and constraints of the computer system.
(c) Describe how control unit determine instruction type after the
decoding using flowchart for instruction cycle.
The control unit of a computer is responsible for controlling the flow of data between the CPU, memory, and input/output devices. After an instruction has been fetched from memory, the control unit must decode the instruction to determine its type and then execute it. The following flowchart describes how the control unit determines the instruction type after decoding:
- The instruction is fetched from memory and stored in the instruction register (IR).
- The opcode portion of the instruction is extracted from the IR.
- The opcode is used to determine the type of instruction (e.g. arithmetic, logical, branching).
- The control unit generates a sequence of microinstructions to carry out the instruction.
- The microinstructions are executed in the appropriate order to complete the instruction.
- Once the instruction has been executed, the control unit returns to the fetch phase to fetch the next instruction.
For example, consider the following instruction: ADD R1, R2, R3
- The instruction is fetched from memory and stored in the instruction register (IR).
- The opcode portion of the instruction (ADD) is extracted from the IR.
- The opcode is used to determine that this is an arithmetic instruction.
- The control unit generates a sequence of microinstructions to add the contents of registers R2 and R3 and store the result in register R1.
- The microinstructions are executed in the appropriate order to complete the addition.
- Once the addition has been completed, the control unit returns to the fetch phase to fetch the next instruction.
In this way, the control unit determines the type of instruction and generates the appropriate sequence of microinstructions to execute it.
OR
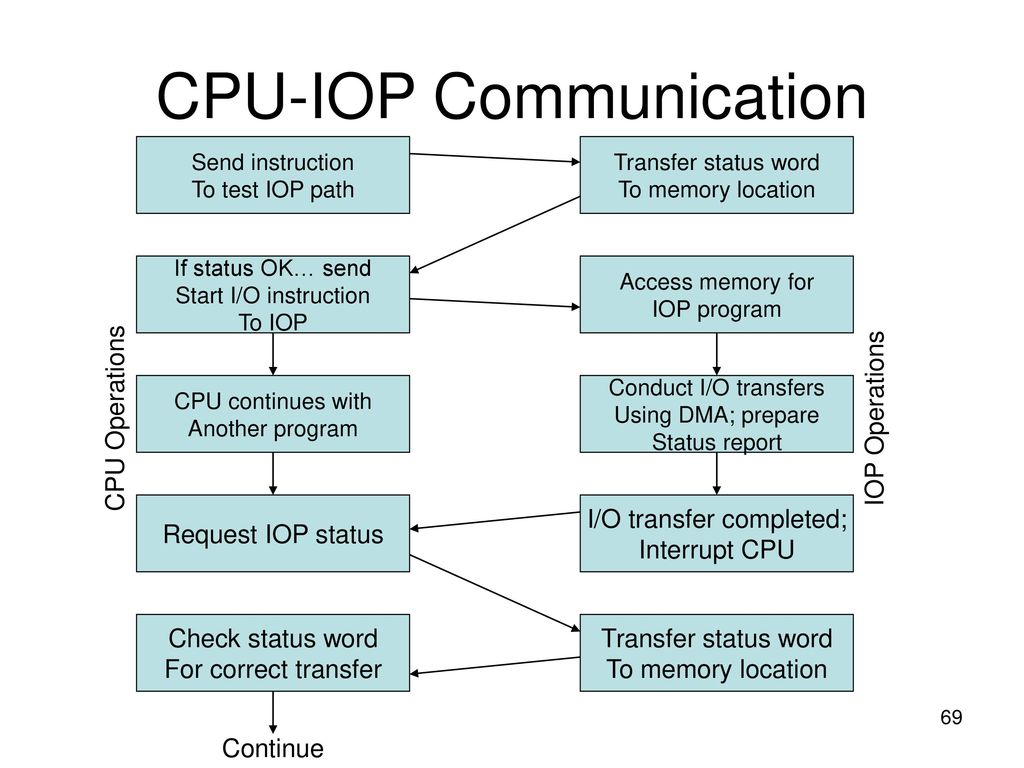
(a) Prepare flowchart of CPU-IOP communication.
(b) Differentiate RISC and CISC architecture.
RISC and CISC are two different computer architecture designs that have evolved over time. Here are the main differences between them:
- Instruction set complexity: CISC processors have a complex instruction set, which means that a single instruction can perform multiple operations. RISC processors, on the other hand, have a reduced instruction set, which means that each instruction performs a single operation.
- Number of registers: RISC processors have more registers compared to CISC processors. This is because RISC processors rely on register operations rather than memory operations.
- Memory access: RISC processors have a load/store architecture, which means that all operations are performed on registers, and memory access is only allowed through load and store instructions. CISC processors, on the other hand, allow direct memory access.
- Pipelining: RISC processors are designed for pipelining, which means that multiple instructions can be executed simultaneously. CISC processors are not as efficient for pipelining because of their complex instruction set.
- Compiler optimization: RISC processors rely on compiler optimization to achieve better performance. CISC processors, on the other hand, rely on hardware to achieve better performance.
- Power consumption: RISC processors consume less power compared to CISC processors because they have a simpler instruction set.
Example: A common example of a CISC processor is the Intel x86 architecture, while a common example of a RISC processor is the ARM architecture.
In summary, CISC processors have a complex instruction set, allow direct memory access, and rely on hardware for performance optimization, while RISC processors have a reduced instruction set, rely on compiler optimization, and are designed for pipelining.
(c) What is cache memory? Interpret direct addressing mapping with
diagram.
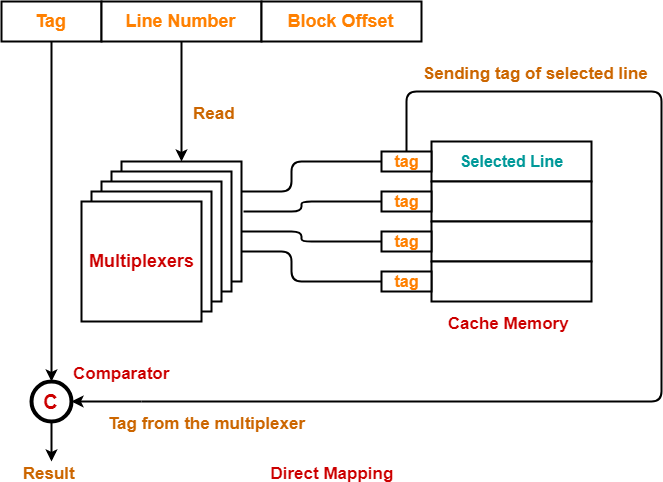
Cache memory is a high-speed memory that stores frequently used data or instructions, allowing for faster access than retrieving from the main memory. Direct addressing mapping is a cache mapping technique where each block in the main memory is mapped to exactly one block in the cache memory.
In direct addressing mapping, the address of the data or instruction is divided into three parts: the tag, the index, and the offset. The tag is used to identify which block in the main memory the data or instruction is located in. The index is used to determine which block in the cache memory the data or instruction is mapped to. The offset is used to determine the exact location of the data or instruction within the block.
The following diagram illustrates the direct addressing mapping technique for a cache memory with 4 blocks and a block size of 4 words:
(a) Draw and criticize memory hierarchy in a computer system.
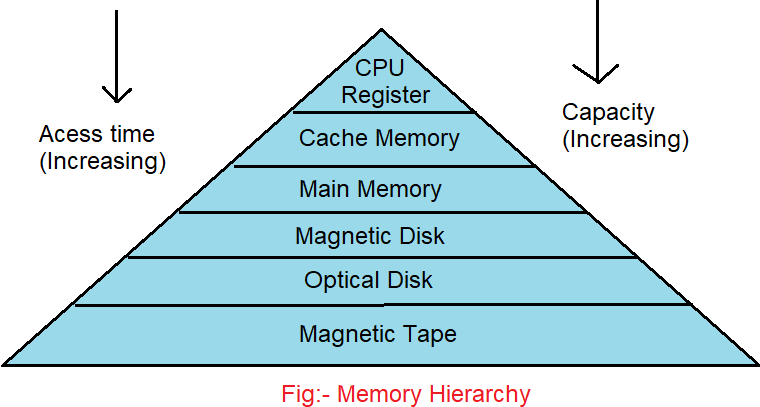
Memory hierarchy is an important aspect of computer architecture that aims to provide a balance between the speed and capacity of memory. The memory hierarchy consists of multiple levels of memory, each with different access times, capacities, and costs.
The different levels of memory hierarchy are:
- Registers: The fastest memory in a computer system, which are directly accessible by the processor.
- Cache: The next level of memory, which stores frequently accessed data and instructions. It is faster than main memory but has a smaller capacity.
- Main Memory: The main memory of the computer system, which stores the operating system, programs, and data. It is slower than cache but has a larger capacity.
- Secondary Storage: The long-term storage of the computer system, which includes hard disk drives, solid-state drives, and optical drives.
- Tertiary Storage: The archival storage of the computer system, which includes tapes and other forms of offline storage.
Criticisms of the memory hierarchy include the following:
- Cost: Each level of memory adds cost to the computer system, and designing a memory hierarchy that balances cost and performance can be challenging.
- Complexity: The memory hierarchy adds complexity to the computer system, making it more difficult to design and program.
- Cache coherence: Maintaining cache coherence between multiple processors can be difficult and may require additional hardware and software support.
- Capacity: Each level of memory has a finite capacity, which can lead to cache misses and slower performance.
- Latency: Accessing memory at higher levels of the hierarchy can take longer than accessing lower levels of memory, which can impact performance.
Despite these criticisms, the memory hierarchy remains an essential part of modern computer architecture, allowing for faster access to frequently used data and instructions while still providing sufficient capacity for less frequently used data and instructions.
(b) Write an Assembly level program for addition of 50 numbers.
TITLE "TO PRINT THE SUM OF NATURAL NUMBERS FROM 1 TO 50" .MODEL SMALL .STACK .DATA VAL DB 1 .CODE MAIN PROC MOV AX,@DATA MOV DS,AX MOV BX,1 MOV CX,50 MOV AX,0 TOP: ADD AX,BX INC BX LOOP TOP XOR DX,DX MOV BX,50 DIV BX AAM ADD AX,3030H PUSH DX MOV DH,AL MOV DL,AH MOV AH,02H INT 21H MOV DL,DH MOV AH,02H INT 21H POP AX AAM ADD AX,3030H PUSH DX MOV DH,AL MOV DL,AH MOV AH,02H INT 21H MOV DL,DH MOV AH,02H INT 21H MOV AH,4CH INT 21H MAIN ENDP END MAIN
(c) Draw the flowchart of first pass of the assembler and explain working
of the same.
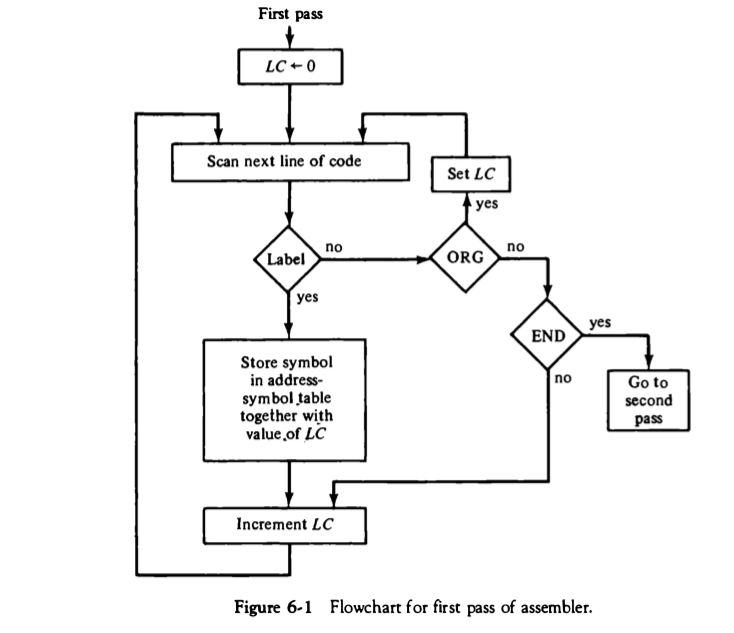
The first pass of an assembler involves scanning the source code and creating a symbol table that contains the location of each label and the value of each constant. The assembler reads the source code line by line and performs the following tasks:
- It reads the source code line and removes any comments.
- It checks if the line contains a label. If it does, it adds the label to the symbol table along with its location.
- It checks if the line contains a constant. If it does, it adds the constant to the symbol table along with its value.
- It calculates the location of the current instruction based on the location of the previous instruction and the length of the previous instruction. This is necessary because the size of each instruction can vary depending on the instruction set architecture.
- It generates machine code for the current instruction using the opcode and operands.
- It stores the machine code in memory at the appropriate location.
The first pass of the assembler does not generate the final machine code. Its main purpose is to create a symbol table that will be used in the second pass of the assembler to generate the final machine code. The symbol table contains information about the location of labels and the values of constants, which is required for the assembler to resolve all the symbolic references in the source code.
OR
(a) Interpret the following instructions: INP, ISZ and LDA
- INP: INP is an input instruction used in assembly language programming. It is used to input data from an input device, such as a keyboard or a scanner, into a memory location.
- ISZ: ISZ is an increment and skip if zero instruction. It is used to increment the contents of a memory location by 1 and then checks whether the result is zero or not. If it is zero, then the program counter is incremented by one, and the next instruction is executed. If it is not zero, the program counter is not changed, and the current instruction is repeated.
- LDA: LDA is a load accumulator instruction used in assembly language programming. It is used to load the contents of a memory location into the accumulator register.
(b) Write an Assembly level program to move one block of data to another
location.
Here is an example program in Assembly language that moves a block of data from one location to another:
ORG 1000H
; initialize variables
Source DB 12H, 34H, 56H, 78H
Dest DB 0, 0, 0, 0
Count DW 4
MOV CX, Count
MOV SI, OFFSET Source
MOV DI, OFFSET Dest
; loop through the block of data and copy it
LOOP:
MOV AL, [SI]
MOV [DI], AL
INC SI
INC DI
LOOP LOOP
END
This program starts at memory location 1000H and initializes three variables: Source, Dest, and Count. Source contains the data to be moved, Dest is the destination for the data, and Count specifies the number of bytes to move.
The program then uses MOV instructions to copy the data from Source to Dest using a loop. The CX register is used to control the loop and is initialized to Count. The SI and DI registers are used as pointers to the source and destination data, respectively. The loop copies each byte from Source to Dest and then increments the pointers. The loop continues until CX reaches zero.
Finally, the program ends with the END directive.
(c) List out modes of transfer. Formulate direct memory access technique
in detail.
Modes of data transfer in a computer system are:
- Programmed I/O
- Interrupt-driven I/O
- Direct Memory Access (DMA)
Direct Memory Access (DMA) is a technique used to transfer data directly between I/O devices and memory without involving the CPU. This technique is used to reduce the CPU’s workload and increase the overall system performance.
The steps involved in the DMA transfer are as follows:
- The CPU sets up the DMA controller with the transfer parameters, including the starting memory address, the device address, and the number of bytes to transfer.
- The DMA controller requests control of the system bus from the CPU.
- The CPU releases the bus to the DMA controller, which then reads or writes data directly to or from memory and I/O devices.
- Once the transfer is complete, the DMA controller returns control of the system bus to the CPU.
The DMA controller transfers the data between memory and I/O devices using the Direct Memory Access Transfer Mode. In this mode, the DMA controller directly reads or writes data to or from memory and I/O devices without the intervention of the CPU.
This technique is used in situations where a large amount of data needs to be transferred between memory and an I/O device. It allows the CPU to perform other tasks while the data transfer is taking place, thus increasing system performance.
(a) Summarize major hazards in pipelined execution.
Pipelining is a technique used in computer processors to improve performance by breaking down instructions into smaller steps that can be executed in parallel. However, pipelining can lead to hazards that can slow down the execution of instructions.
The major hazards in pipelined execution are:
- Structural Hazards: Occur when multiple instructions need the same hardware resource at the same time. For example, if the pipeline stages require access to the same memory or ALU, they will need to be shared. Structural hazards can be resolved by adding additional hardware or by rearranging the pipeline stages.
- Data Hazards: Occur when an instruction depends on the results of a previous instruction that is still being processed in the pipeline. This can cause the pipeline to stall, waiting for the results of the previous instruction. Data hazards can be resolved by forwarding the data from the previous instruction to the dependent instruction, or by stalling the pipeline until the data is available.
- Control Hazards: Occur when the pipeline needs to make a decision based on a conditional instruction, such as a branch instruction, before the results of the instruction are available. Control hazards can cause the pipeline to stall, waiting for the results of the conditional instruction. Control hazards can be resolved by using branch prediction techniques or by delaying the execution of conditional instructions until the results are available.
By identifying and resolving these hazards, pipelined execution can be optimized for high performance.
(b) What is a data dependency conflict in instruction pipeline?
Recommend solutions for data dependency conflicts.
In instruction pipeline, data dependency conflict occurs when an instruction depends on data produced by a previous instruction that has not yet completed its execution in the pipeline. This dependency creates a conflict as the pipeline cannot move forward until the data is available, leading to pipeline stalls and reduced performance.
There are several solutions to data dependency conflicts in instruction pipelines:
- Forwarding or data forwarding: This technique involves bypassing the intermediate stages of the pipeline and directly forwarding the data from the output of the earlier stage to the input of the later stage that needs it. This solution reduces pipeline stalls and improves performance.
- Stalling or pipeline flushing: This technique involves stopping the pipeline until the required data is available. This solution eliminates the possibility of data hazards but can reduce performance.
- Register renaming: This technique involves duplicating registers to eliminate the dependency between instructions and avoid data hazards. This solution reduces pipeline stalls and improves performance.
- Speculative execution: This technique involves executing instructions speculatively based on the assumption that the data dependency will not occur. If the assumption is incorrect, the pipeline is flushed, and the instructions are re-executed. This solution can improve performance but requires additional hardware support.
- Compiler optimization: This technique involves restructuring the code to reduce data dependencies and improve pipeline performance. This solution requires changes to the code and may not always be feasible.
Overall, the choice of solution depends on the design goals and constraints of the pipeline. A combination of these solutions may be used to optimize pipeline performance.
(c) Demonstrate four-segment instruction pipeline in detail
Here is an example of a four-segment instruction pipeline, which is a simplified model of a typical pipeline used in modern CPUs:
- Instruction Fetch (IF): In this stage, the pipeline fetches the instruction from memory or cache and stores it in the Instruction Register (IR). The program counter (PC) points to the next instruction to be fetched, and the PC value is updated to point to the next instruction.
- Instruction Decode (ID): In this stage, the pipeline decodes the instruction in the IR and determines the type of instruction and the operands it needs. The pipeline also checks for any data dependencies with previously executed instructions and stalls if necessary.
- Execute (EX): In this stage, the pipeline executes the instruction using the operands obtained in the previous stage. The execution stage can be divided into several sub-stages, depending on the complexity of the instruction.
- Write Back (WB): In this stage, the pipeline writes the result of the instruction execution back to the register file or memory. If the instruction was a load or store, the pipeline performs the necessary memory operations.
Let’s consider an example of a simple four-segment pipeline executing the following instructions:
ADD R1, R2, R3
SUB R4, R1, R5
AND R6, R2, R7
OR R8, R9, R10
Here’s how the pipeline would execute each instruction:
Clock cycle 1: IF: Fetch the ADD instruction from memory and store it in the IR ID: Decode the ADD instruction and determine the operands EX: Execute the ADD instruction and compute the result WB: Write the result to the register file
Clock cycle 2: IF: Fetch the SUB instruction from memory and store it in the IR ID: Decode the SUB instruction and determine the operands (stalled as R1 is not ready yet) EX: Wait for the result of the ADD instruction to be available and execute the SUB instruction WB: Write the result to the register file
Clock cycle 3: IF: Fetch the AND instruction from memory and store it in the IR ID: Decode the AND instruction and determine the operands EX: Execute the AND instruction and compute the result WB: Write the result to the register file
Clock cycle 4: IF: Fetch the OR instruction from memory and store it in the IR ID: Decode the OR instruction and determine the operands EX: Execute the OR instruction and compute the result WB: Write the result to the register file
In this example, the pipeline stalls in the second clock cycle because the SUB instruction requires the result of the ADD instruction, which is not yet available. However, the pipeline can still achieve a significant speedup compared to executing the instructions sequentially.
OR
(a) Sketch Microinstruction code format. Quote BR and CD field in brief.
Microinstruction code format typically includes several fields, such as the operation code (opcode), register selection fields, control fields, and address fields. One common microinstruction code format is the horizontal microinstruction format, which arranges the fields horizontally in the microinstruction word.
Here is an example of a horizontal microinstruction code format:
| opcode | RS1 | RS2 | RS3 | control fields | address field |
- Opcode: This field specifies the operation to be performed by the microinstruction. The opcode field can be used to encode operations such as load, store, arithmetic, logic, and control operations.
- RS1, RS2, RS3: These fields specify the registers to be used in the microinstruction. Depending on the processor architecture, these fields may specify general-purpose registers, special-purpose registers, or flags.
- Control fields: These fields specify the control signals to be generated by the microinstruction. Examples of control fields include enable signals, clock signals, and data path signals.
- Address field: This field specifies the memory address or the next microinstruction address to be executed.
Two common fields in the control fields are:
- BR (Branch) field: This field specifies the type of branch to be taken by the processor. The BR field can encode different types of branches such as unconditional, conditional, and indirect branches.
- CD (Condition) field: This field specifies the condition for a conditional branch. The CD field can encode conditions such as equal, not equal, less than, greater than, and carry. The CD field is used to compare two values and generate a control signal based on the comparison result.
(b) Compare following terms:
Write through-cache and Write back cache.
Spatial locality and Temporal locality
- Write-through cache and write-back cache:
Write-through and write-back are two techniques used in computer caches to manage data updates. In a write-through cache, every write to the cache is immediately written to the main memory as well. In contrast, in a write-back cache, data is only written back to the main memory when it is evicted from the cache. Here are some key differences between write-through and write-back cache:
- Write-through cache has lower write performance compared to write-back cache since every write operation involves an additional write to the main memory.
- Write-back cache has higher read performance compared to write-through cache since it has more space available to store frequently accessed data.
- Write-through cache is easier to implement than write-back cache because it does not require any additional logic to handle evictions and writebacks.
- Write-back cache is more complex and can be more prone to data inconsistencies if not properly implemented.
- Spatial locality and temporal locality:
Spatial locality and temporal locality are two principles that describe how data is accessed in computer systems.
Spatial locality refers to the tendency of a program to access data that is located near other recently accessed data. For example, when accessing an array, the program is likely to access the adjacent elements as well, due to the way arrays are stored in memory.
Temporal locality refers to the tendency of a program to access the same data repeatedly over a short period. For example, a loop that repeatedly processes a large array will exhibit high temporal locality, as the same data is accessed multiple times.
Here are some key differences between spatial locality and temporal locality:
- Spatial locality is concerned with accessing nearby data, while temporal locality is concerned with repeated access to the same data.
- Spatial locality is important for cache performance because it allows caching of nearby data to reduce memory access latency.
- Temporal locality is important for cache performance because it allows caching of frequently accessed data to reduce memory access latency.
- Both spatial and temporal locality are important factors in determining cache performance and overall system performance.
Overall, spatial and temporal locality are both important principles for optimizing computer system performance, and understanding them can help in designing more efficient caching and memory systems.
(c) Elaborate flynn’s classification scheme with proper diagram.
Flynn’s classification scheme is a taxonomy that categorizes computer architectures based on the number of instruction streams and data streams that can be processed simultaneously. The scheme was introduced by Michael J. Flynn in 1966 and is still widely used in computer science.
The Flynn’s classification scheme divides computer architectures into four categories based on two dimensions: instruction stream and data stream. The instruction stream dimension indicates the number of concurrent instruction streams, while the data stream dimension indicates the number of concurrent data streams.
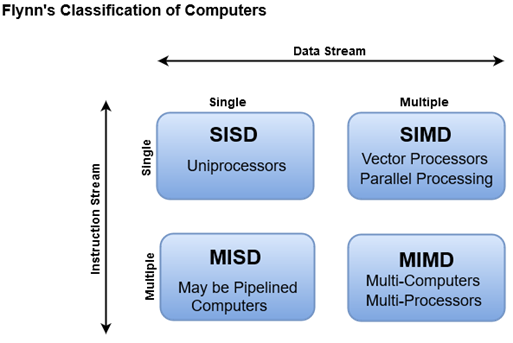
Here are the four categories of computer architectures in Flynn’s classification scheme:
- SISD (Single Instruction Stream, Single Data Stream): This is the traditional type of computer architecture, in which a single instruction stream controls the flow of operations, and a single data stream provides the operands for the instructions. This type of architecture is used in most traditional von Neumann computers.
- SIMD (Single Instruction Stream, Multiple Data Stream): In this architecture, a single instruction stream is used to perform the same operation on multiple data streams simultaneously. SIMD computers are optimized for tasks that can be performed using parallelism, such as graphics processing and scientific simulations.
- MISD (Multiple Instruction Stream, Single Data Stream): In this architecture, multiple instruction streams are executed on a single data stream. MISD computers are not commonly used in practice, but they can be used in safety-critical systems, such as aerospace or nuclear power plants, where multiple redundant processors can check each other’s results.
- MIMD (Multiple Instruction Stream, Multiple Data Stream): This architecture allows for multiple instruction streams and data streams to be processed simultaneously, providing the highest level of parallelism. MIMD computers can be further divided into two subcategories: shared-memory and distributed-memory architectures. In shared-memory MIMD computers, all processors share a common memory, while in distributed-memory MIMD computers, each processor has its own local memory and communicates with other processors via a communication network.
Flynn’s classification scheme provides a useful framework for understanding the capabilities and limitations of different computer architectures. By categorizing architectures based on their ability to handle instruction and data streams, it helps to identify which architectures are best suited for different types of applications.
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.”