Here, We provide Data Structure GTU Paper Solution Winter 2020 . Read the Full DS GTU paper solution given below.
Data Structure GTU Old Paper Winter 2020 [Marks : 56] : Click Here
(a) Compare array and linked list.
Arrays and linked lists are two common data structures used in programming. Here are some key differences between the two:
- Memory allocation: In an array, memory is allocated in contiguous blocks, while in a linked list, memory can be allocated anywhere and is not necessarily contiguous.
- Size flexibility: Arrays have a fixed size, meaning that once an array is created, its size cannot be changed. In contrast, linked lists can grow or shrink in size dynamically, as new nodes are added or removed.
- Access time: Accessing an element in an array is faster than accessing an element in a linked list because the array’s memory is contiguous, and its elements can be accessed directly with an index. In contrast, accessing an element in a linked list requires traversing the list from the beginning to the desired element.
- Insertion and deletion: Inserting or deleting an element in an array requires shifting all the elements to the right or left of the inserted or deleted element. In contrast, inserting or deleting an element in a linked list only requires modifying a few pointers.
- Memory usage: Arrays require a fixed amount of memory, while linked lists require additional memory for pointers.
- Sequential processing: Arrays are better suited for sequential processing, such as sorting or searching, while linked lists are better suited for applications that require frequent insertions or deletions, such as a queue or a stack.
In summary, arrays and linked lists have their own strengths and weaknesses, and which one to use depends on the specific requirements of the problem being solved.
(b) Compare primitive and non primitive data types data structures.
Primitive and non-primitive data types are two categories of data types in programming. Here are some differences between the two:
- Definition: Primitive data types are basic or fundamental data types that are built into a programming language. Non-primitive data types are more complex and are built using primitive data types and/or other non-primitive data types.
- Memory allocation: Primitive data types are usually allocated a fixed amount of memory, while non-primitive data types can be dynamically allocated and resized.
- Value assignment: Primitive data types hold a single value at a time, while non-primitive data types can hold multiple values or objects.
- Operations: Primitive data types have a limited set of operations that can be performed on them, while non-primitive data types can have complex operations and methods defined for them.
- Immutability: Primitive data types are often immutable, meaning that their values cannot be changed once they are assigned. In contrast, non-primitive data types can often be mutable, meaning that their properties can be modified.
- Default values: Primitive data types have default values assigned to them, while non-primitive data types do not. For example, the default value for an int in Java is 0, while the default value for an object is null.
In summary, primitive data types are simpler, fixed-size data types built into a programming language, while non-primitive data types are more complex data structures built using primitive data types and/or other non-primitive data types. Non-primitive data types can be more flexible and offer more functionality, but can also be more memory-intensive and harder to work with.
(c) Write an algorithm to perform insert and delete operations on simple queue.
Insert
Step1: IFREAR = MAX - 1
Write OVERFLOW
Go to step
[END OF IF]
Step 2: IF FRONT = -1 and REAR = -1
SET FRONT = REAR = 0
ELSE
SET REAR = REAR + 1
[END OF IF]
Step 3: Set QUEUE[REAR] = NUM
Step 4: EXIT
Delete
Step 1: IF FRONT = -1 or FRONT > REAR
Write UNDERFLOW
ELSE
SET VAL = QUEUE[FRONT]
SET FRONT = FRONT + 1
[END OF IF]
Step 2: EXIT
(a) Search the number 50 from the given data using binary search technique. Illustrate the searching process. 10, 14, 20, 39, 41, 45, 49, 50, 60
- Low = 0, High = 8
- search_ele = 50
- Mid_ele_idx = (low + high)/2
- = (0+8)/2
- = 4
Is 41 = 50? No
The list now is 45 49 50 60
- Low =5, high= 8
- Mid_ele_idx = (low + high) /2
- = (5+8)/2
- = 6
Is 49 = 50? No
The list now is 50 60
- Low = 7, high = 8
- Mid_ele_idx = (low + high)/2
- = (7+8)/2
- = 7
Is 50 = 50 ? yes
location = 7
Output: The search element 50 is found at location 7.
(b) Apply merge sort algorithm to the following elements. 20, 10, 5, 15, 25, 30, 50, 35
Step 1: Divide the unsorted list into n sub-lists, each containing 1 element. Here, the sub-lists would be [20], [10], [5], [15], [25], [30], [50], [35].
Step 2: Merge sub-lists to produce newly sorted sub-lists until there is only 1 sub-list remaining.
Step 3: Compare the first element of each sub-list and merge them in the order that results in a sorted list.
Sub-list 1: [20] Sub-list 2: [10] New sub-list: [10, 20]
Sub-list 1: [5] Sub-list 2: [15] New sub-list: [5, 15]
Sub-list 1: [25] Sub-list 2: [30] New sub-list: [25, 30]
Sub-list 1: [50] Sub-list 2: [35] New sub-list: [35, 50]
Sub-list 1: [10, 20] Sub-list 2: [5, 15] New sub-list: [5, 10, 15, 20]
Sub-list 1: [25, 30] Sub-list 2: [35, 50] New sub-list: [25, 30, 35, 50]
Sub-list 1: [5, 10, 15, 20] Sub-list 2: [25, 30, 35, 50] New sub-list: [5, 10, 15, 20, 25, 30, 35, 50]
Step 4: The final sub-list [5, 10, 15, 20, 25, 30, 35, 50] is the sorted list using merge sort.
(c) Write a ‘C’ program for bubble sort.
#include <stdio.h>
int main()
{
int array[100], n, c, d, swap;
printf("Enter number of elements\n");
scanf("%d", &n);
printf("Enter %d integers\n", n);
for (c = 0; c < n; c++)
scanf("%d", &array[c]);
for (c = 0 ; c < n - 1; c++)
{
for (d = 0 ; d < n - c - 1; d++)
{
if (array[d] > array[d+1]) /* For decreasing order use '<' instead of '>' */
{
swap = array[d];
array[d] = array[d+1];
array[d+1] = swap;
}
}
}
printf("Sorted list in ascending order:\n");
for (c = 0; c < n; c++)
printf("%d\n", array[c]);
return 0;
}
(a) What is stack? Why do we use multiple stacks?
A stack is a linear data structure that follows the Last-In-First-Out (LIFO) principle. In a stack, elements are added and removed from the top of the stack only.
Stacks are widely used in programming and computer science, as they provide an efficient way to store and retrieve data. Some common applications of stacks include expression evaluation, backtracking, and recursion.
Multiple stacks can be used in situations where different types of data need to be stored separately. For example, in a web browser, multiple stacks may be used to keep track of the pages visited in different tabs or windows. In a multi-threaded program, each thread may have its own stack to store its local variables and function calls.
Another use of multiple stacks is in implementing specific data structures, such as a double-ended queue (deque), which requires two stacks to support insertion and deletion at both ends.
In some cases, multiple stacks may also be used to improve the performance of certain algorithms. For example, in a parallel computing system, multiple stacks may be used to distribute the load across different processors, allowing the program to run faster.
In summary, multiple stacks are used to organize and separate different types of data, implement specific data structures, and improve the performance of certain algorithms.
(b) Convert the following infix expressions to their prefix and postfix equivalents.
1. A*B+C/D
2. (A*B)+(C/D)-(D+E)
1. Infix expression: A*B+C/D
- Prefix expression:
Start by converting the infix expression to postfix expression: AB * CD / +
Reverse the postfix expression: + / CD * AB
Result: + / CD * AB
- Postfix expression:
Start by converting the infix expression to postfix expression using the standard postfix algorithm: AB * CD / +
Result: AB * CD / +
Note: The postfix expression is already in the required form and there is no need to reverse it.
2. Infix expression: (A*B)+(C/D)-(D+E)
- Prefix expression:
Start by converting the infix expression to postfix expression: AB * CD / + DE + –
Reverse the postfix expression: – + DE + / CD * AB
Result: – + DE + / CD * AB
- Postfix expression:
Start by converting the infix expression to postfix expression using the standard postfix algorithm: AB * CD / + DE + –
Result: AB * CD / + DE + –
(c) What is priority queue? Discuss its applications and implementation details.
A priority queue is a type of queue that arranges elements based on their priority values. Elements with higher priority values are typically retrieved before elements with lower priority values.
In a priority queue, each element has a priority value associated with it. When you add an element to the queue, it is inserted in a position based on its priority value. For example, if you add an element with a high priority value to a priority queue, it may be inserted near the front of the queue, while an element with a low priority value may be inserted near the back.
Applications of priority queue:
- Dijkstra’s Shortest Path Algorithm using priority queue: In this algorithm, priority queue can be used to extract the minimum when the graph is stored in the form of adjacency list or matrix.
- Prim’s Algorithm using priority queue: Priority queue is used to implement the Prim’s algorithm to store the keys of nodes and extract the minimum value node at every step.
- Data Compression: Priority queue is used for compressing the data in Huffman coding.
- Operating Systems: Priority queue is also used in operating systems for interrupt handling, load balancing (load balancing on server).
- Heap Sort: In Heap sort is basically implemented using Heap data structure which is implemented using priority queue.
- Artificial Intelligence
- *A Search Algorithm:** This algorithm is used to find the shortest path between two vertices of a weighted graph, trying out the most promising route first. It uses priority queue to keep track of unexplored routes, the one for which a lower bound on the total path length is smallest is given highest priority.
Implementation of Priority Queue
The priority queue can be implemented in four ways that include arrays, linked list, heap data structure and binary search tree. The heap data structure is the most efficient way of implementing the priority queue, so we will implement the priority queue using a heap data structure in this topic. Now, first we understand the reason why heap is the most efficient way among all the other data structures.
(a) Evaluate following Expression using stack 53+62/*35*+
Input: str = “53+62/*35*+ “
Output: 39
Explanation:
- Scan 5, it’s a number, so push it to stack. Stack contains ‘5’
- Scan 3, again a number, push it to stack, stack now contains ‘5 3’ (from bottom to top)
- Scan +, it’s an operator, pop two operands from stack, apply the + operator on operands, we get 5+3 which results in 8. We push the result 8 to stack. The stack now becomes ‘8’.
- Scan6, again a number, push it to stack, stack now contains ‘8 6’ .
- Scan2, again a number, push it to stack, stack now contains ‘8 6 2’ .
- Scan /, it’s an operator, pop two operands from stack, apply the / operator on operands, we get 6/2 which results in 3. We push the result 3 to stack. The stack now becomes ‘8 3’.
- Scan *, it’s an operator, pop two operands from stack, apply the * operator on operands, we get 8*3 which results in 24. We push the result 24 to the stack. The stack now becomes ‘24’.
- Scan 3, again a number, push it to stack, stack now contains ‘24 3’
- Scan 5, it’s a number, so push it to stack. Stack contains ’24 3 5’
- Scan *, it’s an operator, pop two operands from stack, apply the * operator on operands, we get 3*5 which results in 15. We push the result 15 to the stack. The stack now becomes ’24 15’.
- Scan +, it’s an operator, pop two operands from stack, apply the + operator on operands, we get 24+15 which results in 39. We push the result 39 to stack. The stack now becomes ‘39’.
- There are no more elements to scan, we return the top element from the stack (which is the only element left in a stack).
(b) Design an algorithm to perform insert operation in circular queue.
STEP 1 START
STEP 2 Store the element to insert in linear data structure
STEP 3 Check if (front == 0 && rear == MAX-1) || (front == rear+1) then queue Overflow else goto step 4
STEP 4 Check if (front == -1) then front = 0; rear= 0; else goto step 5
STEP 5 Check if (rear == MAX -1) then rear=0; else rear= rear+1; and goto step 6
STEP 6 Insert element cqueue_arr[rear] = item;
STEP 7 STOP
(c) Design an algorithm to merge two linked list.
Let LLOne and LLTwo be the head pointer of two sorted linked list and resultHead and resultTail are the head and tail pointer of merged linked list.
- Initilaize resultHead and resultTail to NULL. resultHead = resultTail = NULL;
- If first linked list is empty, then attach whole of second list at the tail of merged linked list. if(LLOne == NULL) then resultTail->next = LLTwo;
- If second linked list is empty, then attach whole of first list at the tail of merged linked list. if(LLTwo == NULL) then resultTail->next = LLOne;
- Check which of the current nodes of both linked list is smaller and then remove it from linked list.
- Add the smalled node at the tail of merged linked list.
- Repeat above process, until one of the linked list or both becomes empty.
- Return head pointer of merged linked list. return resultHead.
(a) Define: 1. Acyclic graph 2. Leaf node 3. Complete binary tree
1. Acyclic graph :
A graph is called an acyclic graph if zero cycles are present, and an acyclic graph is the complete opposite of a cyclic graph.
2. Leaf node :
The node of the tree, which doesn’t have any child node, is called a leaf node. A leaf node is the bottom-most node of the tree. There can be any number of leaf nodes present in a general tree. Leaf nodes can also be called external nodes.
3. Complete binary tree :
A binary tree is said to be a complete binary tree when all the levels are completely filled except the last level, which is filled from the left.
(b) For following expressions, construct the corresponding binary tree
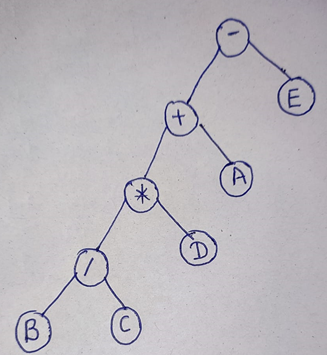
1. A+B/C*D-E
1. A+B/C*D-E
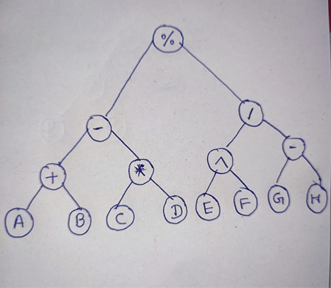
2. ((A+B)-(C*D))%((E^F)/(G-H))
(c) How are graphs represented inside a computer’s memory? Which method do you prefer and why?
There are several ways to represent a graph in a computer’s memory. Some of the most common methods are:
- Adjacency matrix: In this representation, the graph is stored as a 2D array where each row and column represents a vertex in the graph. If there is an edge between two vertices, the corresponding entry in the matrix is set to 1, otherwise it is set to 0. This method is easy to implement and allows constant time access to edge information, but can be inefficient for sparse graphs.
- Adjacency list: In this representation, the graph is stored as a list of vertices, where each vertex contains a list of its neighboring vertices. This method is efficient for sparse graphs, as it only stores information about the edges that exist in the graph. However, it can be slower for dense graphs.
- Edge list: In this representation, the graph is stored as a list of edges, where each edge is represented as a tuple of the form (u, v), where u and v are the endpoints of the edge. This method is simple and efficient for sparse graphs, but can be less efficient for dense graphs.
The choice of graph representation method depends on various factors, such as the size and density of the graph, the operations that need to be performed on the graph, and the available memory. In general, adjacency lists are often preferred for sparse graphs, while adjacency matrices are preferred for dense graphs. Edge lists are a good choice when the focus is on the edges of the graph rather than the vertices.
(a) Define: 1. Connected graph 2. Threaded tree 3. Degree of node
- Connected graph: A connected graph is a graph in which there is a path between every pair of vertices. In other words, there are no disconnected components in the graph. A graph can be disconnected if there are one or more vertices that are not reachable from any other vertex.
- Threaded tree: A threaded tree is a binary tree in which all the null pointers are replaced with references to other nodes in the tree, called threads. There are two types of threads: left threads and right threads. A left thread of a node is a reference to the in-order predecessor of the node, while a right thread is a reference to the in-order successor of the node. Threaded trees can be used to traverse the tree in in-order without using a stack or recursion.
- Degree of node: The degree of a node in a graph is the number of edges incident to the node. For a directed graph, there are two types of degrees: in-degree and out-degree. The in-degree of a node is the number of edges that point to the node, while the out-degree is the number of edges that start from the node. In a undirected graph, the degree of a node is the sum of the in-degree and out-degree, since the edges are bidirectional. The degree of a node is a useful measure of the connectivity of the node in the graph.
(b) Differentiate between depth first search and breadth first search.
Depth First Search (DFS) and Breadth First Search (BFS) are two common algorithms used to traverse and search graphs and trees. Here are the main differences between DFS and BFS:
- Order of traversal: DFS traverses a graph or tree by exploring as far as possible along each branch before backtracking, while BFS traverses a graph or tree level by level, exploring all nodes at each level before moving to the next level.
- Memory usage: DFS uses a stack to keep track of the nodes to visit next, while BFS uses a queue to keep track of the nodes to visit next. This means that DFS can be implemented with lower memory usage than BFS, especially for deep graphs or trees.
- Completeness: BFS is guaranteed to find the shortest path between two nodes in an unweighted graph, while DFS is not. This is because BFS explores all nodes at a given level before moving to the next level, ensuring that the shortest path is found first.
- Applications: DFS is commonly used in backtracking, topological sorting, and cycle detection, while BFS is commonly used in pathfinding, shortest path algorithms, and maze solving.
To summarize, DFS and BFS are two different algorithms used to traverse and search graphs and trees. DFS explores as far as possible along each branch before backtracking, while BFS explores all nodes at a given level before moving to the next level. DFS is memory-efficient and useful for certain applications, while BFS is guaranteed to find the shortest path in an unweighted graph and useful for other applications.
(c) Design an algorithm to insert a given value in the binary search tree.
Insert function is used to add a new element in a binary search tree at appropriate location. Insert function is to be designed in such a way that, it must node violate the property of binary search tree at each value.
- Allocate the memory for tree.
- Set the data part to the value and set the left and right pointer of tree, point to NULL.
- If the item to be inserted, will be the first element of the tree, then the left and right of this node will point to NULL.
- Else, check if the item is less than the root element of the tree, if this is true, then recursively perform this operation with the left of the root.
- If this is false, then perform this operation recursively with the right sub-tree of the root.
Insert (TREE, ITEM)
- Step 1: IF TREE = NULL
Allocate memory for TREE
SET TREE -> DATA = ITEM
SET TREE -> LEFT = TREE -> RIGHT = NULL
ELSE
IF ITEM < TREE -> DATA
Insert(TREE -> LEFT, ITEM)
ELSE
Insert(TREE -> RIGHT, ITEM)
[END OF IF]
[END OF IF] - Step 2: END
(a) Explain basic file operations
Basic file operations refer to the actions that can be performed on files in a computer’s file system. Here are some of the most common file operations:
- Creating a file: This operation involves creating a new file in the file system with a specified name and location. In most programming languages, this can be done using a built-in function or class that provides access to the file system.
- Opening a file: This operation involves opening an existing file in the file system for reading, writing, or both. In most programming languages, this can be done using a built-in function or class that provides access to the file system. When opening a file, the file handle or file descriptor is returned, which can be used to read or write data to the file.
- Reading from a file: This operation involves reading data from an open file into a buffer or variable. This can be done using a built-in function or method that provides access to the file handle or file descriptor.
- Writing to a file: This operation involves writing data to an open file. This can be done using a built-in function or method that provides access to the file handle or file descriptor.
- Closing a file: This operation involves closing an open file when it is no longer needed. This is an important operation to ensure that the data in the file is saved properly and that system resources are released.
- Deleting a file: This operation involves removing an existing file from the file system. In most programming languages, this can be done using a built-in function or class that provides access to the file system.
These are some of the basic file operations that can be performed on files in a computer’s file system. Proper handling of file operations is important to ensure that the data is saved and accessed correctly, and that system resources are used efficiently.
(b) List out applications of hashing.
Message Digest:
This is an application of cryptographic Hash Functions. Cryptographic hash functions are the functions which produce an output from which reaching the input is close to impossible. This property of hash functions is called irreversibility.
Password Verification:
Cryptographic hash functions are very commonly used in password verification
Data Structures(Programming Languages):
Various programming languages have hash table based Data Structures. The basic idea is to create a key-value pair where key is supposed to be a unique value, whereas value can be same for different keys. This implementation is seen in unordered_set & unordered_map in C++, HashSet & HashMap in java, dict in python etc.
Compiler Operation:
The keywords of a programming language are processed differently than other identifiers. To differentiate between the keywords of a programming language(if, else, for, return etc.) and other identifiers and to successfully compile the program, the compiler stores all these keywords in a set which is implemented using a hash table.
Rabin-Karp Algorithm:
One of the most famous applications of hashing is the Rabin-Karp algorithm. This is basically a string-searching algorithm which uses hashing to find any one set of patterns in a string. A practical application of this algorithm is detecting plagiarism.
Linking File name and path together:
When moving through files on our local system, we observe two very crucial components of a file i.e. file_name and file_path. In order to store the correspondence between file_name and file_path the system uses a map(file_name, file_path)which is implemented using a hash table.
Game Boards:
In a game like Tic-Tac-Toe or chess the position of the game may be stored using hash table.
(c) What is file organization? Briefly summarize different file organizations.
File Organization
File organization ensures that records are available for processing. It is used to determine an efficient file organization for each base relation.
For example, if we want to retrieve employee records in alphabetical order of name. Sorting the file by employee name is a good file organization. However, if we want to retrieve all employees whose marks are in a certain range, a file is ordered by employee name would not be a good file organization.
Types of File Organization
1. Sequential access file organization
- Storing and sorting in contiguous block within files on tape or disk is called as sequential access file organization.
- In sequential access file organization, all records are stored in a sequential order. The records are arranged in the ascending or descending order of a key field.
- Sequential file search starts from the beginning of the file and the records can be added at the end of the file.
- In sequential file, it is not possible to add a record in the middle of the file without rewriting the file.
2. Direct access file organization
- Direct access file is also known as random access or relative file organization.
- In direct access file, all records are stored in direct access storage device (DASD), such as hard disk. The records are randomly placed throughout the file.
- The records does not need to be in sequence because they are updated directly and rewritten back in the same location.
- This file organization is useful for immediate access to large amount of information. It is used in accessing large databases.
- It is also called as hashing.
3. Indexed sequential access file organization
- Indexed sequential access file combines both sequential file and direct access file organization.
- In indexed sequential access file, records are stored randomly on a direct access device such as magnetic disk by a primary key.
- This file have multiple keys. These keys can be alphanumeric in which the records are ordered is called primary key.
- The data can be access either sequentially or randomly using the index. The index is stored in a file and read into memory when the file is opened.
(a) Give a brief note on indexing
Indexing in data structures is a technique used to optimize the search and retrieval of data from large collections of data. An index is a data structure that contains a mapping of the values in a dataset to their locations in memory or on disk. Indexing enables fast access to data based on a search key or a range of keys.
There are different types of indexing techniques, including:
- Sequential indexing: This technique uses a sequential list of keys to locate the data items in memory or on disk. This is the simplest form of indexing, but it can be slow for large datasets.
- Binary search indexing: This technique uses a sorted list of keys and a binary search algorithm to locate the data items in memory or on disk. This is faster than sequential indexing, but it requires that the keys be sorted.
- B-tree indexing: This technique uses a balanced tree structure to store the keys and data items. This enables fast access to data items based on a range of keys, and it is commonly used in databases.
- Hash indexing: This technique uses a hash function to map the keys to the locations of the data items in memory or on disk. This is the fastest form of indexing, but it can be sensitive to collisions in the hash function.
Indexing is a powerful technique that can significantly improve the performance of data access and retrieval operations. However, it requires additional memory and processing overhead to maintain the index structure. The choice of indexing technique depends on the size and complexity of the dataset, the access patterns, and the performance requirements of the application.
(b) Build a chained hash table of 10 memory locations. Insert the keys 131, 3, 4, 21, 61, 24, 7, 97, 8, 9 in hash table using chaining. Use h(k) = k mod m. (m=10)
Calculate the hash value for key 131 using the formula h(k) = k mod m where m=10. The hash value is 1.
Create a linked list at memory location 1 and insert key 131 into the linked list.
Calculate the hash value for key 3 using the formula h(k) = k mod m where m=10. The hash value is 3.
Create a linked list at memory location 3 and insert key 3 into the linked list.
Calculate the hash value for key 4 using the formula h(k) = k mod m where m=10. The hash value is 4.
Insert key 4 into the linked list at memory location 4.
Calculate the hash value for key 21 using the formula h(k) = k mod m where m=10. The hash value is 1.
Insert key 21 into the linked list at memory location 1.
Calculate the hash value for key 61 using the formula h(k) = k mod m where m=10. The hash value is 1.
Insert key 61 into the linked list at memory location 1.
Calculate the hash value for key 24 using the formula h(k) = k mod m where m=10. The hash value is 4.
Insert key 24 into the linked list at memory location 4.
Calculate the hash value for key 7 using the formula h(k) = k mod m where m=10. The hash value is 7.
Create a linked list at memory location 7 and insert key 7 into the linked list.
Calculate the hash value for key 97 using the formula h(k) = k mod m where m=10. The hash value is 7.
Insert key 97 into the linked list at memory location 7.
Calculate the hash value for key 8 using the formula h(k) = k mod m where m=10. The hash value is 8.
Create a linked list at memory location 8 and insert key 8 into the linked list.
Calculate the hash value for key 9 using the formula h(k) = k mod m where m=10. The hash value is 9.
Create a linked list at memory location 9 and insert key 9 into the linked list.
So, the final hash table would look like: [131 -> 21 -> 61, null, 3, 4 -> 24, 7 -> 97, 8, 9].
(c) Consider the hash table of size 10. Using quadratic probing, insert the keys 72, 27, 36, 24, 63, 81, and 101 into hash table. Take c1=1 and c2=3.
- Calculate the hash value for key 72 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 72 at position 2.
- Calculate the hash value for key 27 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 27 at position 1.
- Calculate the hash value for key 36 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 36 at position 5.
- Calculate the hash value for key 24 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 24 at position 0.
- Calculate the hash value for key 63 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 63 at position 8.
- Calculate the hash value for key 81 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Place key 81 at position 9.
- Calculate the hash value for key 101 using the formula: h(x) = (h1(x) + c1 * i + c2 * i^2) mod m where m=10.
- Key 101 cannot be placed, as all positions have been filled.
So, the final hash table would look like: [24, 27, 72, null, 36, null, null, null, 63, 81].
Read More : DS GTU Paper Solution Winter 2021
Read More : DBMS GTU Paper Solution Winter 2020
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.