Here, We provide Data Structure GTU Paper Solution Winter 2021 . Read the Full DS GTU paper solution given below.
Data Structure GTU Old Paper Winter 2021 [Marks : 56] : Click Here
Question: 1
(a) What is time complexity? Explain with an example.
Time complexity refers to the amount of time it takes for an algorithm to run and complete its task. It is used to measure the efficiency of an algorithm and is typically represented using big O notation.
An example of time complexity can be seen in the case of sorting algorithms. The bubble sort algorithm has a time complexity of O(n^2) because it compares and swaps elements in a list multiple times, resulting in a quadratic increase in the amount of time it takes to sort a larger list. On the other hand, the quicksort algorithm has a time complexity of O(n log n) as it can divide and conquer the list more efficiently, resulting in a linear increase in time with a logarithmic factor.
(b) Explain malloc and free functions in ‘C’. Also, discuss the advantages of
dynamic over static memory allocation.
The malloc (memory allocation) and free functions in C are used to dynamically allocate and deallocate memory at runtime. The malloc function is used to reserve a block of memory of a specified size and returns a pointer to the first byte of the allocated memory.
The free function is used to release the memory that was previously allocated by the malloc function.
Example:
int* ptr;
ptr = (int*) malloc(sizeof(int)); // Allocates memory for an integer
*ptr = 5; // assigns value 5 to the memory location
free(ptr); // releases the memory allocated to ptr
Advantages of dynamic memory allocation over static memory allocation:
- Flexibility: Dynamic memory allocation allows for allocating and deallocating memory as needed at runtime, making it more flexible than static memory allocation where memory is allocated at compile-time.
- Efficiency: Dynamic memory allocation allows for better use of memory resources by allocating only the necessary amount of memory and releasing it when no longer needed.
- Memory Conservation: Dynamic memory allocation prevents memory wastage by allocating only the required amount of memory and deallocating it when not in use.
- Dynamic data structures: Dynamic memory allocation allows for the creation of dynamic data structures such as linked lists and trees that can change their size during the execution of a program.
- Large data storage: Dynamic memory allocation allows to handle of large amounts of data that cannot be accommodated in static memory allocation.
(c) Explain the following: (i) priority queue (ii) primitive data structures (iii) non-primitive data structures (iv) linear data structures (v) nonlinear data structures (vi)
applications of stack (vii) sparse matrix
i) Priority queue: A priority queue is a type of data structure where each element has an associated priority value. Elements are inserted and removed based on their priority, with the element of highest priority being removed first.
ii) Primitive data structures: Primitive data structures are basic building blocks of a program and include data types such as integers, floats, and characters. They are the most basic form of data structures and cannot be broken down further.
iii) Non-primitive data structures: Non-primitive data structures are more complex and are built on top of primitive data structures. Examples include arrays, linked lists, and trees.
iv) Linear data structures: Linear data structures are data structures that can be represented as a linear sequence of elements, where each element is connected to the next element in the sequence. Examples include arrays, linked lists, and stacks.
v) Nonlinear data structures: Nonlinear data structures are data structures that cannot be represented as a linear sequence of elements. Examples include trees and graphs.
vi) Applications of stack: Stacks are used in many applications such as memory management, parsing expressions, backtracking, and undo/redo operations.
vii) Sparse matrix: A sparse matrix is a matrix where most of the elements are zero. It is used to represent large sparse data sets, where the majority of the elements are zero and only a small number of non-zero elements need to be stored. This allows for efficient storage and manipulation of large data sets.
Question: 2
(a) Write an algorithm for infix to postfix conversion.
Here is an algorithm for infix to postfix conversion:
Initialize an empty stack and an empty output string.
Iterate through each character in the infix expression:
a. If the character is an operand, add it to the output string.
b. If the character is an operator, check the following:
i. If the stack is empty or the character is an open parenthesis, push it onto the stack.
ii. If the character is a closing parenthesis, pop operators from the stack and add them to the output string until an open parenthesis is encountered.
iii. If the character is an operator, pop operators from the stack and add them to the output string until the stack is empty or the top operator on the stack has a lower precedence than the current operator. Then push the current operator onto the stack.
After iterating through the entire expression, pop any remaining operators from the stack and add them to the output string.
The output string now contains the postfix expression.(b) Write an algorithm to evaluate postfix expression. Explain the working of the
algorithm using an appropriate example.
Here is an algorithm for evaluating postfix expressions:
Initialize an empty stack.
Iterate through each character in the postfix expression:
a. If the character is an operand, push it onto the stack.
b. If the character is an operator, pop the top two elements from the stack, perform the operation using the operator and the two elements, and push the result back onto the stack.
After iterating through the entire expression, the final result will be the top element on the stack.Postfix expression: 2 3 4 + *
Initialize an empty stack.
Iterate through characters:
i. 2 is an operand, push 2 onto the stack.
ii. 3 is an operand, push 3 onto the stack.
iii. 4 is an operand, push 4 onto the stack.
iv. + is an operator, pop 4 and 3 from the stack, perform 3+4=7 and push 7 onto the stack.
v. * is an operator, pop 7 and 2 from the stack, perform 2*7=14 and push 14 onto the stack.
After iterating through the entire expression, the final result, 14, is the top element on the stack.(c) Write a ‘C’ program to reverse a string using stack.
#include <stdio.h>
#include <string.h>
#define MAX_SIZE 100
char stack[MAX_SIZE];
int top = -1;
void push(char c) {
if (top == MAX_SIZE-1) {
printf("Error: Stack overflow\n");
return;
}
stack[++top] = c;
}
char pop() {
if (top == -1) {
printf("Error: Stack underflow\n");
return -1;
}
return stack[top--];
}
void reverse(char str[]) {
int length = strlen(str);
for (int i = 0; i < length; i++) {
push(str[i]);
}
for (int i = 0; i < length; i++) {
str[i] = pop();
}
}
int main() {
char str[MAX_SIZE];
printf("Enter a string: ");
scanf("%s", str);
reverse(str);
printf("Reversed string: %s\n", str);
return 0;
}
(c) Write an algorithm to (i) insert, and (ii) delete elements in a circular queue.
i) Inserting an element in a circular queue:
- Initialize a circular queue with a fixed size and two pointers, front and rear, to keep track of the front and rear of the queue.
- Check if the queue is full (rear+1 mod size = front) before inserting a new element. If the queue is full, return an error message.
- If the queue is not full, increment the rear pointer by one and insert the new element at the rear of the queue.
- If the rear pointer reaches the end of the queue, set it back to the beginning of the queue (rear = rear mod size).
ii) Deleting an element from a circular queue:
- Initialize a circular queue with a fixed size and two pointers, front and rear, to keep track of the front and rear of the queue.
- Check if the queue is empty (front = rear) before deleting an element. If the queue is empty, return an error message.
- If the queue is not empty, increment the front pointer by one and remove the element at the front of the queue.
- If the front pointer reaches the end of the queue, set it back to the beginning of the queue (front = front mod size).
Question: 3
(a) Write user defined ‘C’ function to insert a node at a specific location in singly
linked list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
void insertNode(struct Node** head, int data, int position) {
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
newNode->data = data;
if (position == 0) {
newNode->next = *head;
*head = newNode;
return;
}
struct Node* temp = *head;
for (int i = 0; i < position - 1; i++) {
temp = temp->next;
}
newNode->next = temp->next;
temp->next = newNode;
}
(b) Write a user-defined ‘C’ function to delete a node from end in circular linked
list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
void deleteNode(struct Node** head) {
struct Node* temp = *head;
struct Node* prev = NULL;
if(*head == NULL) {
return;
}
// find the last node
while(temp->next != *head) {
prev = temp;
temp = temp->next;
}
if(prev == NULL) {
*head = NULL;
free(temp);
} else {
prev->next = *head;
free(temp);
}
}
(c) Write a ‘C’ program to implement a queue using linked list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
struct Queue {
struct Node* front;
struct Node* rear;
};
void init(struct Queue* q) {
q->front = NULL;
q->rear = NULL;
}
int isEmpty(struct Queue* q) {
return (q->front == NULL);
}
void enqueue(struct Queue* q, int data) {
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = NULL;
if (q->rear == NULL) {
q->front = q->rear = newNode;
return;
}
q->rear->next = newNode;
q->rear = newNode;
}
int dequeue(struct Queue* q) {
if (isEmpty(q)) {
printf("Queue is empty\n");
return -1;
}
struct Node* temp = q->front;
int data = temp->data;
q->front = q->front->next;
if (q->front == NULL) {
q->rear = NULL;
}
free(temp);
return data;
}
int main() {
struct Queue q;
init(&q);
enqueue(&q, 1);
enqueue(&q, 2);
enqueue(&q, 3);
printf("%d ", dequeue(&q));
printf("%d ", dequeue(&q));
printf("%d ", dequeue(&q));
return 0;
}
Question: 3
(a) Write a user-defined ‘C’ function to insert a node at the end in a circular linked list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
void insertEnd(struct Node** head, int data) {
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = *head;
if(*head == NULL) {
*head = newNode;
newNode->next = *head;
return;
}
struct Node* temp = *head;
while(temp->next != *head) {
temp = temp->next;
}
temp->next = newNode;
}
(b) Write a user-defined ‘C’ function to delete a node from a specific location in
a doubly linked list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
struct Node* prev;
};
void deleteNode(struct Node** head, int position) {
if (*head == NULL) {
return;
}
struct Node* temp = *head;
if (position == 0) {
*head = temp->next;
(*head)->prev = NULL;
free(temp);
return;
}
for (int i = 0; temp != NULL && i < position; i++) {
temp = temp->next;
}
if (temp == NULL) {
return;
}
if (temp->next != NULL) {
temp->next->prev = temp->prev;
}
if (temp->prev != NULL) {
temp->prev->next = temp->next;
}
free(temp);
}
(c) Write a ‘C’ program to implement stack using a linked list.
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
struct Stack {
struct Node* top;
};
void init(struct Stack* s) {
s->top = NULL;
}
int isEmpty(struct Stack* s) {
return (s->top == NULL);
}
void push(struct Stack* s, int data) {
struct Node* newNode = (struct Node*) malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = s->top;
s->top = newNode;
}
int pop(struct Stack* s) {
if (isEmpty(s)) {
printf("Stack is empty\n");
return -1;
}
struct Node* temp = s->top;
int data = temp->data;
s->top = s->top->next;
free(temp);
return data;
}
int main() {
struct Stack s;
init(&s);
push(&s, 1);
push(&s, 2);
push(&s, 3);
printf("%d ", pop(&s));
printf("%d ", pop(&s));
printf("%d ", pop(&s));
return 0;
}
Question: 4
(a) Construct a binary tree from the traversals given below:
Inorder: D, B, A, E, G, C, H, F, I
Preorder: A, B, D, C, E, G, F, H, I
(b) Write a short on AVL tree.
AVL tree is a type of self-balancing binary search tree that maintains a balance factor for each node. The balance factor of a node is the difference between the heights of its left and right subtrees. AVL trees are named after their inventors, Adelson-Velsky and Landis.
The main feature of AVL tree is that it maintains the balance factor of each node such that it is always -1, 0, or 1. If the balance factor of a node is greater than 1 or less than -1, the tree is considered unbalanced and needs to be rebalanced. AVL trees are rebalanced by performing rotations on the nodes.
The rotations performed on AVL tree are:
- Left rotation: This is performed when a node has a balance factor of 2 and its right subtree has a balance factor of -1 or 0. In this case, the node is rotated to the left, and its right child becomes the new root of the subtree.
- Right rotation: This is performed when a node has a balance factor of -2 and its left subtree has a balance factor of 1 or 0. In this case, the node is rotated to the right, and its left child becomes the new root of the subtree.
- Left-right rotation: This is performed when a node has a balance factor of 2 and its right subtree has a balance factor of 1. In this case, the right child is rotated to the right, and then the node is rotated to the left.
- Right-left rotation: This is performed when a node has a balance factor of -2 and its left subtree has a balance factor of -1. In this case, the left child is rotated to the left, and then the node is rotated to the right.
The main advantage of AVL tree is that it ensures that the tree is balanced at all times, which allows for efficient operations such as insertion, deletion, and search. However, the AVL tree has a higher overhead compared to other data structures, as it requires additional space to store the balance factors for each node.
AVL trees are used in various applications such as compilers, databases, and computer networks. They are also commonly used as a benchmark to compare the performance of other self-balancing tree data structures.
(c) Explain the concept of B-tree with a suitable example and list its applications.
B-tree is a type of self-balancing tree data structure that allows for efficient operations on large datasets. It is commonly used for storing large amounts of data on disk, where disk access times are much slower than in-memory access times. B-trees are designed to minimize the number of disk accesses needed to retrieve data by storing large amounts of data in each node and minimizing the height of the tree.
The main properties of B-tree are:
- Each node can have multiple children and keys.
- The keys are sorted in each node in ascending order.
- All leaf nodes are at the same level.
- The root node has at least two children.
- All other nodes have at least m/2 children and at most m children, where m is the order of the tree.
Here is an example of a B-tree with an order of 3:
[3, 7, 12]
/ | \
[1, 2] [4, 5, 6] [10, 11]
/ \ | \
[-2, -1] [0] [8, 9] [13, 14]In this example, the order of the tree is 3, so each node can have at most 3 children. The keys are sorted in each node, and all leaf nodes are at the same level. The root node has three children, and all other nodes have at least one child.
B-trees have many applications in computer science, including:
- File systems: B-trees are commonly used in file systems to store file and directory data on disk.
- Databases: B-trees are used to store large amounts of data in databases, allowing for efficient retrieval and modification of data.
- Network routers: B-trees can be used to store routing tables in network routers, allowing for efficient routing of data packets.
- Compiler symbol tables: B-trees are used to store compiler symbol tables, allowing for efficient lookup of symbols during compilation.
- DNS servers: B-trees can be used to store DNS zone data, allowing for efficient lookup of domain names.
Question: 4
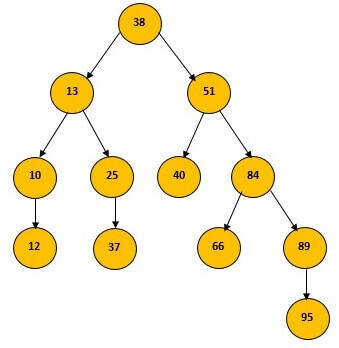
(a) Construct a binary search tree from the following numbers.
38, 13, 51, 10, 12, 40, 84, 25, 89, 37, 66, 95
(b) Explain BFS and DFS.
BFS stands for Breadth-first search, it is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph) and explores the neighbor nodes first, before moving to the next level neighbors. It uses a queue data structure to remember to get the next vertex to visit from.
DFS stands for Depth-first search, it is an algorithm for traversing or searching tree or graph data structures. It starts at the tree root (or some arbitrary node of a graph) and explores as far as possible along each branch before backtracking. It uses a stack data structure to remember to get the next vertex to visit from.

(c) Explain B+ tree with example.
B+ Tree is an extension of B Tree which allows efficient insertion, deletion and search operations.
In B Tree, Keys and records both can be stored in the internal as well as leaf nodes. Whereas, in B+ tree, records (data) can only be stored on the leaf nodes while internal nodes can only store the key values.
The leaf nodes of a B+ tree are linked together in the form of a singly linked lists to make the search queries more efficient.
B+ Tree are used to store the large amount of data which can not be stored in the main memory. Due to the fact that, size of main memory is always limited, the internal nodes (keys to access records) of the B+ tree are stored in the main memory whereas, leaf nodes are stored in the secondary memory.
A B+ tree of order 3 is shown in the following figure.

Advantages of B+ Tree
- Records can be fetched in equal number of disk accesses.
- Height of the tree remains balanced and less as compare to B tree.
- We can access the data stored in a B+ tree sequentially as well as directly.
- Keys are used for indexing.
- Faster search queries as the data is stored only on the leaf nodes.
Question: 5
(a) Explain Prim’s algorithm.
Prim’s algorithm is a greedy algorithm used to find the minimum spanning tree of a weighted undirected graph. The minimum spanning tree is a tree that spans all the vertices in the graph with the minimum total edge weight.
The algorithm starts with an arbitrary vertex and repeatedly adds the minimum weight edge that connects to an unvisited vertex until all vertices are visited.
Here are the steps to perform Prim’s algorithm:
- Initialize a set of visited vertices and a set of unvisited vertices. Set the visited set to be empty and the unvisited set to contain all the vertices in the graph.
- Choose an arbitrary vertex from the unvisited set and add it to the visited set.
- For each edge connected to the chosen vertex, add the edge to a priority queue ordered by edge weight.
- While the priority queue is not empty, do the following:
- Pop the minimum weight edge from the priority queue.
- If the edge connects a visited vertex to an unvisited vertex, add the unvisited vertex to the visited set and add the edge to the minimum spanning tree.
- If the edge connects two visited vertices, discard the edge.
- When all vertices are visited, the minimum spanning tree is the set of edges in the tree.
Prim’s algorithm has a time complexity of O(E log V), where E is the number of edges and V is the number of vertices in the graph. It is an efficient algorithm for finding the minimum spanning tree of a graph and is often used in network design and optimization problems.
(b) Write a ‘C’ program for selection sort.
#include <stdio.h>
void selection(int arr[], int n)
{
int i, j, small;
for (i = 0; i < n-1; i++) // One by one move boundary of unsorted subarray
{
small = i; //minimum element in unsorted array
for (j = i+1; j < n; j++)
if (arr[j] < arr[small])
small = j;
// Swap the minimum element with the first element
int temp = arr[small];
arr[small] = arr[i];
arr[i] = temp;
}
}
void printArr(int a[], int n) /* function to print the array */
{
int i;
for (i = 0; i < n; i++)
printf("%d ", a[i]);
}
int main()
{
int a[] = { 12, 31, 25, 8, 32, 17 };
int n = sizeof(a) / sizeof(a[0]);
printf("Before sorting array elements are - \n");
printArr(a, n);
selection(a, n);
printf("\nAfter sorting array elements are - \n");
printArr(a, n);
return 0;
} (c) List out different hash methods and explain any three.
Different hash functions:
- Division Method: This method involves dividing the key by the table size and taking the remainder as the index. It is a simple method, but it can lead to clustering if the key values are not uniformly distributed.
- Multiplication Method: This method involves multiplying the key by a constant factor between 0 and 1, and then taking the fractional part of the result multiplied by the table size as the index. This method can help reduce clustering and is widely used in practice.
- Folding Method: This method involves breaking the key into smaller parts (usually of equal size), adding the parts together, and then taking the remainder of the sum as the index. This method can help ensure that all parts of the key are used, even if the key values are not uniformly distributed.
- Mid-Square Method: This method involves squaring the key, taking the middle digits of the result, and then using the result as the index. This method is simple, but it can produce poor results if the key values are not well-distributed.
- Radix Transformation Method: This method involves converting the key into a different radix (e.g., base 10 to base 2), and then using the resulting digits as the index. This method can help distribute the key values more evenly, but it can also be computationally expensive.
Folding Method
The folding method is a hash method used to map a key to an index in a hash table. It involves breaking the key into smaller parts, adding those parts together, and then taking the remainder of the sum as the index.
For example, suppose we have a key value of 123456789 and a hash table of size 10. We can break the key into two parts, such as:
12 + 34 + 56 + 78 + 9
We add these parts together to get:
12 + 34 + 56 + 78 + 9 = 189
Then, we take the remainder of 189 divided by 10 to get the index:
189 % 10 = 9
Therefore, the key value 123456789 would be mapped to index 9 in the hash table.
The folding method can help ensure that all parts of the key are used, even if the key values are not uniformly distributed. However, it can also be time-consuming if the key values are very large or if the number of parts is very high. Therefore, it is not always the best choice for hashing large datasets.
Question: 5
(a) Define terms with respect to file: fields, records, database
In the context of a file, the following terms are commonly used:
- Fields: A field is a unit of data within a record that is designed to hold a specific piece of information. For example, in a file containing information about employees, each record might have fields for the employee’s name, address, age, and salary.
- Records: A record is a collection of related data fields that are grouped together to represent a single entity or transaction. In our example, each record would contain all of the information about a single employee.
- Database: A database is a collection of related data that is stored and organized in a way that enables efficient retrieval and manipulation of the data. In the context of files, a database typically consists of one or more files that are organized and managed together to provide a comprehensive view of the data. A database might contain multiple files, each representing a different type of data or set of records, and may include various tools for querying and analyzing the data.
(b) Compare sequential and binary search methods.
Sequential search and binary search are two algorithms used to search for an element in a list. The main differences between them are as follows:
- Sequential search: It is a simple linear search algorithm that sequentially checks each element of a list until a match is found or the end of the list is reached. It is suitable for small lists, but it can be slow for larger lists. It has a time complexity of O(n), where n is the number of elements in the list.
- Binary search: It is a more efficient algorithm that works by dividing the search interval in half at each step, and then eliminating half of the remaining elements based on whether the search element is greater than or less than the middle element. It is suitable for larger lists and has a time complexity of O(log n), where n is the number of elements in the list. However, it requires that the list be sorted before the search.
Here are some other differences between sequential search and binary search:
- Sequential search does not require that the list be sorted, while binary search does.
- Binary search is faster than sequential search for large lists, but slower for small lists.
- Binary search requires more memory than sequential search, since it needs to keep track of the middle element and search intervals.
- Binary search is a divide-and-conquer algorithm, while sequential search is a simple iterative algorithm.
In summary, binary search is generally faster and more efficient than sequential search, but it requires that the list be sorted and uses more memory. Sequential search is simpler and easier to implement, but it can be slow for larger lists.
(c) Apply quick sort for the following data:
9, 7, 5, 11, 12, 2, 14, 3, 10, 6
To apply quick sort on the given data, we can follow these steps:
- Choose a pivot element. We can choose the first element as the pivot.
- Partition the array such that all elements smaller than the pivot are on the left side, and all elements greater than the pivot are on the right side.
- Recursively apply steps 1 and 2 to the left and right partitions.
- Combine the left and right partitions to get the sorted array.
Here’s an implementation of quick sort in Java to sort the given data:
public class QuickSort {
public static void main(String[] args) {
int[] data = {9, 7, 5, 11, 12, 2, 14, 3, 10, 6};
quickSort(data, 0, data.length - 1);
System.out.println(Arrays.toString(data));
}
public static void quickSort(int[] data, int low, int high) {
if (low < high) {
int pivot = partition(data, low, high);
quickSort(data, low, pivot - 1);
quickSort(data, pivot + 1, high);
}
}
public static int partition(int[] data, int low, int high) {
int pivot = data[low];
int i = low + 1;
int j = high;
while (i <= j) {
while (i <= j && data[i] <= pivot) {
i++;
}
while (i <= j && data[j] > pivot) {
j--;
}
if (i < j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
int temp = data[low];
data[low] = data[j];
data[j] = temp;
return j;
}
}The quickSort() method takes an array data, a low index low, and a high index high. It first checks if the low index is less than the high index. If yes, it calls the partition() method to partition the array around a pivot element, and recursively applies the quick sort algorithm to the left and right partitions.
The partition() method takes an array data, a low index low, and a high index high. It chooses the first element as the pivot, and then iterates over the array using two indices i and j. It moves i from left to right, and j from right to left, until they meet. At each step, it swaps the elements at indices i and j if they are in the wrong order relative to the pivot. When i and j meet, it swaps the pivot element with the element at index j. It returns the index j, which is the new position of the pivot element.
Read More : DS GTU Paper Solution Winter 2021
Read More : DBMS GTU Paper Solution Winter 2020
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.