Here, We provide Database Management System GTU Paper Solution Winter 2021. Read the Full DBMS gtu paper solution given below.
DBMS GTU Old Paper Winter 2021 [Marks : 70] : Click Here
Question: 1
(a) Explain three levels of data abstraction.
There are mainly 3 levels of data abstraction:
Data abstraction is the process of hiding complex implementation details of a system and presenting a simplified view of the data to the user. This helps in managing the complexity of the system and makes it easier to use and understand. There are three levels of data abstraction in a database management system:
- Physical Level: The physical level of data abstraction is the lowest level of abstraction. At this level, the database management system deals with the physical storage of data. It is concerned with how the data is stored on the storage media such as hard disks, tapes, or any other storage device. The physical level describes the data structures used for storing data, the file organization techniques, and the access methods used to retrieve data.
- Logical Level: The logical level of data abstraction is the second level of abstraction. At this level, the database management system deals with the logical representation of data. It is concerned with the meaning of the data stored in the database. The logical level describes the relationships between data elements, the constraints applied on data, and the operations that can be performed on the data.
- View Level: The view level of data abstraction is the highest level of abstraction. At this level, the database management system deals with the user interface or the user view of the data. It is concerned with the way the data is presented to the user. The view level describes the user’s view of the data, the user’s access privileges, and the way the data is presented to the user. Different users may have different views of the same data, depending on their needs and requirements.
Example: In case of storing customer data,
Physical level – it will contains block of storages (bytes,GB,TB,etc)
Logical level – it will contain the fields and the attributes of data.
View level – it works with CLI or GUI access of database
(b) Describe Data Definition Language and Data Manipulation Language.
Data Definition Language (DDL) and Data Manipulation Language (DML) are two types of SQL commands that are used to manage and manipulate data in a database management system.
- Data Definition Language (DDL): DDL is a set of SQL commands used to define, create, modify, and delete database objects such as tables, views, indexes, and constraints. The following are some of the commonly used DDL commands:
- CREATE: used to create a new database object such as a table, view, or index
- ALTER: used to modify an existing database object such as adding or deleting columns from a table
- DROP: used to delete a database object such as a table or view
- TRUNCATE: used to remove all data from a table
- Data Manipulation Language (DML): DML is a set of SQL commands used to manipulate data in a database. The following are some of the commonly used DML commands:
- SELECT: used to retrieve data from a database table
- INSERT: used to insert new data into a table
- UPDATE: used to update existing data in a table
- DELETE: used to delete data from a table
In summary, DDL is used to create and modify the structure of the database, while DML is used to manipulate the data stored in the database.
(c) What is integrity constraint? Explain primary key, reference key and check constraint with SQL syntax.
- Integrity constraint
Integrity constraints are a set of rules. It is used to maintain the quality of information.
Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected.
Thus, integrity constraint is used to guard against accidental damage to the database.
- Primary key constraint
A primary key constraint depicts a key comprising one or more columns that will help uniquely identify every tuple/record in a table.
Properties :
-No duplicate values are allowed, i.e. Column assigned as primary key should have UNIQUE values only.
-NO NULL values are present in column with Primary key. Hence there is Mandatory value in column having Primary key.
-Only one primary key per table exist although Primary key may have multiple columns.
-No new row can be inserted with the already existing primary key.
-Classified as : a) Simple primary key that has a Single column 2) Composite primary key has Multiple column.
-Defined in Create table / Alter table statement.
Create Table Person
(
Id int NOT NULL PRIMARY KEY,
Name varchar2(20),
Address varchar2(50));
- Reference key constraint
Foreign Key is a column that refers to the primary key/unique key of other table. So it demonstrates relationship between tables and act as cross reference among them.
Properties :
-Parent that is being referenced has to be unique/Primary Key.
-Child may have duplicates and nulls.
-Parent record can be deleted if no child exists.
-Master table cannot be updated if child exists.
-Must reference PRIMARY KEY in primary table.
-Foreign key column and constraint column should have matching data types.
-Records cannot be inserted in child table if corresponding record in master table do not exist.
-Records of master table cannot be deleted if corresponding records in child table exits.
Create table people (no int references person(id),
Fname varchar2(20)); - Check constraint
Check Constraint is used to specify a predicate that every tuple must satisfy in a given relation. It limits the values that a column can hold in a relation.
-The predicate in check constraint can hold a sub query.
-Check constraint defined on an attribute restricts the range of values for that attribute.
-If the value being added to an attribute of a tuple violates the check constraint, the check constraint evaluates to false and the corresponding update is aborted.
-Check constraint is generally specified with the CREATE TABLE command in SQL.
CREATE TABLE student(
StudentID INT NOT NULL,
Name VARCHAR(30) NOT NULL,
Age INT NOT NULL,
GENDER VARCHAR(9),
PRIMARY KEY(ID),
check(Age >= 17)
)Question: 2
(a) Differentiate single-valued and multi-valued attributes with example.
- Single-Valued Attributes
Single valued attributes are those attributes that consist of a single value for each entity instance and can’t store more than one value. The value of these single-valued attributes always remains the same, just like the name of a person.
Example Diagram:
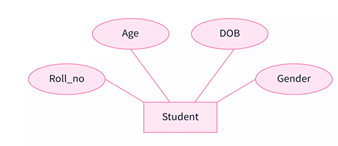
As we can see in the above example, These attributes can store only one value from a set of possible values. Each entity instance can have only one Roll_no, which is a unique, single DOB by which we can calculate age and also fixed gender. Also, we can’t further subdivide these attributes, and hence, they are simple as well as single-valued attributes.
- Multi-Valued Attributes
Multi-valued attributes have opposite functionality to that of single-valued attributes, and as the name suggests, multi-valued attributes can take up and store more than one value at a time for an entity instance from a set of possible values. These attributes are represented by co-centric elliptical shape, and we can also use curly braces { } to represent multi-valued attributes inside it.
Example Diagram:
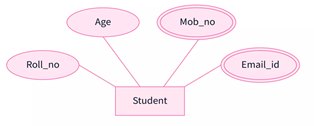
As we can see in the above example, the Student entity has four attributes: Roll_no and Age are simple as well as single-valued attributes as discussed above but Mob_no and Email_id are represented by co-centric ellipse are multi-valued attributes.
(b) What is weak entity? How the weak entity can be converted to the strong entity? Show the symbol for representing weak entity.
An entity type should have a key attribute which uniquely identifies each entity in the entity set, but there exists some entity type for which key attribute can’t be defined. These are called Weak Entity type.
The entity sets which do not have sufficient attributes to form a primary key are known as weak entity sets and the entity sets which have a primary key are known as strong entity sets.
As the weak entities do not have any primary key, they cannot be identified on their own, so they depend on some other entity (known as owner entity). The weak entities have total participation constraint (existence dependency) in its identifying relationship with owner identity. Weak entity types have partial keys. Partial Keys are set of attributes with the help of which the tuples of the weak entities can be distinguished and identified.
A weak entity can be easily converted to a strong entity by adding a primary key or key attribute, which can define the uniqueness constraint. àWeak entity is depend on strong entity to ensure the existence of weak entity. Like strong entity, weak entity does not have any primary key, It has partial discriminator key. Weak entity is represented by double rectangle. The relation between one strong and one weak entity is represented by double diamond.
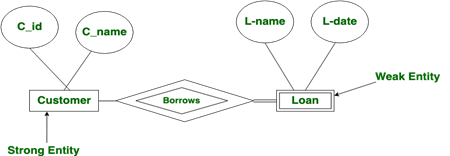
(c)Why do we require E-R model? Explain the term ‘Generalization’, ‘Specialization’ and ‘Aggregation’.
- Importance of E-R model
ER Diagram helps you conceptualize the database and lets you know which fields need to be embedded for a particular entity
ER Diagram gives a better understanding of the information to be stored in a database
It reduces complexity and allows database designers to build databases quickly
It helps to describe elements using Entity-Relationship models
It allows users to get a preview of the logical structure of the database
- Generalization
Generalization is the process of extracting common properties from a set of entities and create a generalized entity from it.
It is a bottom-up approach in which two or more entities can be generalized to a higher level entity if they have some attributes in common.
For Example, STUDENT and FACULTY can be generalized to a higher level entity called PERSON as shown in Figure 1. In this case, common attributes like P_NAME, P_ADD become part of higher entity (PERSON) and specialized attributes like S_FEE become part of specialized entity (STUDENT).
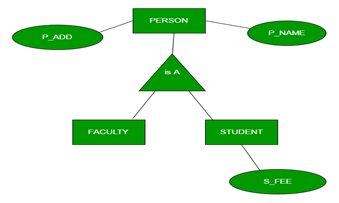
- Specialization
In specialization, an entity is divided into sub-entities based on their characteristics.
It is a top-down approach where higher level entity is specialized into two or more lower level entities.
For Example, EMPLOYEE entity in an Employee management system can be specialized into DEVELOPER, TESTER etc. as shown in Figure 2. In this case, common attributes like E_NAME, E_SAL etc. become part of higher entity (EMPLOYEE) and specialized attributes like TES_TYPE become part of specialized entity (TESTER).
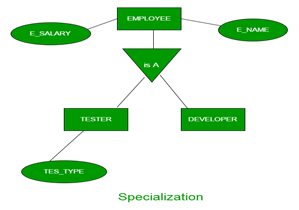
- Aggregation
An ER diagram is not capable of representing relationship between an entity and a relationship which may be required in some scenarios. In those cases, a relationship with its corresponding entities is aggregated into a higher level entity. Aggregation is an abstraction through which we can represent relationships as higher level entity sets.
For Example, Employee working for a project may require some machinery. So, REQUIRE relationship is needed between relationship WORKS_FOR and entity MACHINERY. Using aggregation, WORKS_FOR relationship with its entities EMPLOYEE and PROJECT is aggregated into single entity and relationship REQUIRE is created between aggregated entity and MACHINERY.
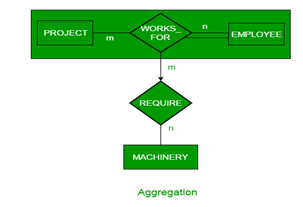
(c) What is the similarity between relational model and E-R model? How the entity, attributes, primary key and relationship are shown in the relational model.
- Similarity between relational model and E-R model
They both assume that information can be described in terms of things (entities vs. records) that have properties (attributes vs. fields), are somehow identified (primary keys vs. primary keys) and are somehow connected (relationships vs. foreign keys).
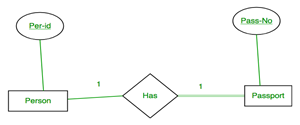
A person has 0 or 1 passport number and Passport is always owned by 1 person. So it is 1:1 cardinality with full participation constraint from Passport.
First Convert each entity and relationship to tables. Person table corresponds to Person Entity with key as Per-Id. Similarly Passport table corresponds to Passport Entity with key as Pass-No. Has Table represents relationship between Person and Passport (Which person has which passport). So it will take attribute Per-Id from Person and Pass-No from Passport.
| Person | Has | Passport | |||||
| Per-Id | Other Person Attribute | Per-Id | Pass-No | Pass-No | Other PassportAttribute | ||
| PR1 | – | PR1 | PS1 | PS1 | – | ||
| PR2 | – | PR2 | PS2 | PS2 | – | ||
| PR3 | – |
As we can see from Table 1, each Per-Id and Pass-No has only one entry in Has Table. So we can merge all three tables into 1 with attributes shown in Table 2. Each Per-Id will be unique and not null. So it will be the key. Pass-No can’t be key because for some person, it can be NULL.
| Per-Id | Other Person Attribute | Pass-No | Other PassportAttribute |
Question: 3
(a) Write Relational Algebra syntax for the following queries. Employee(eno,ename,salary,designation)
Customer(cno,cname,address,city)
1) Find out name of employees who are ‘Manager’.
2) Display name of customers.
3) Retrieve Employee records whose salary is less than 20,000.
- Π ename (σ designation=’Manager’ (Employee))
- Π cname (Customer)
- Π eno, ename, salary, designation (σ salary < 20000 (Employee))
(b) Differentiate lossy decomposition and lossless decomposition.
| Lossless | Lossy |
| The decompositions R1, R2, R2…Rn for a relation schema R are said to be Lossless if there natural join results the original relation R. | The decompositions R1, R2, R2…Rn for a relation schema R are said to be Lossy if there natural join results into addition of extraneous tuples with the original relation R. |
| Formally, Let R be a relation and R1, R2, R3 … Rn be it’s decomposition, the decomposition is lossless if – R1 ⨝ R2 ⨝ R3 …. ⨝ Rn = R | Formally, Let R be a relation and R1, R2, R3 … Rn be it’s decomposition, the decomposition is lossy if – R ⊂ R1 ⨝ R2 ⨝ R3 …. ⨝ Rn |
| There is no loss of information as the relation obtained after natural join of decompositions is equivalent to original relation. Thus, it is also referred to as non-additive join decomposition | There is loss of information as extraneous tuples are added into the relation after natural join of decompositions. Thus, it is also referred to as careless decomposition. |
| The common attribute of the sub relations is a superkey of any one of the relation. | The common attribute of the sub relation is not a |
(c) What is redundancy? Explain insert, update and delete anomalies in database with example.
Redundancy means having multiple copies of same data in the database. This problem arises when a database is not normalized. Suppose a table of student details attributes are: student Id, student name, college name, college rank, course opted.
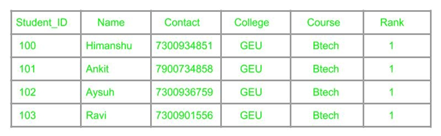
As it can be observed that values of attribute college name, college rank, course is being repeated which can lead to problems. Problems caused due to redundancy are: Insertion anomaly, Deletion anomaly, and Updation anomaly.
- Insertion Anomaly – If a student detail has to be inserted whose course is not being decided yet then insertion will not be possible till the time course is decided for student.

This problem happens when the insertion of a data record is not possible without adding some additional unrelated data to the record.
- Deletion Anomaly – If the details of students in this table are deleted then the details of college will also get deleted which should not occur by common sense.
This anomaly happens when deletion of a data record results in losing some unrelated information that was stored as part of the record that was deleted from a table.
It is not possible to delete some information without losing some other information in the table as well.
- Updation Anomaly – Suppose if the rank of the college changes then changes will have to be all over the database which will be time-consuming and computationally costly.
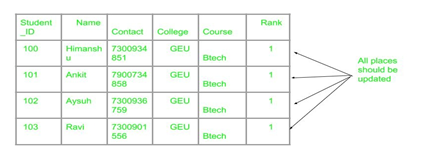
If updation do not occur at all places then database will be in inconsistent state.
Question: 3
(a) Write Relational Algebra syntax for the given queries using the following database.
Employee(eno,ename,salary,designation) Customer(cno,cname,address,city)
1) Find out name of employees who are also customers.
2) Find out name of person who are employees but not customers. 3)Display all names who are either employees or customers.
- Π ename (Employee) ∩ Π cname (Customer)
- Π ename (Employee) – Π cname (Customer)
- Π ename (Employee) U Π cname (Customer)
(b) What is the limitation of index-sequential file? Explain with example how B+ tree overcomes it.
- Limitation of index-sequential file
In this method, records are stored in the file using the primary key. An index value is generated for each primary key and mapped with the record. This index contains the address of the record in the file. If any record has to be retrieved based on its index value, then the address of the data block is fetched and the record is retrieved from the memory.
This method requires extra space in the disk to store the index value.
When the new records are inserted, then these files have to be reconstructed to maintain the sequence.
When the record is deleted, then the space used by it needs to be released. Otherwise, the performance of the database will slow down.
- B+ Tree Overcomes
It uses the same concept of key-index where the primary key is used to sort the records. For each primary key, the value of the index is generated and mapped with the record.
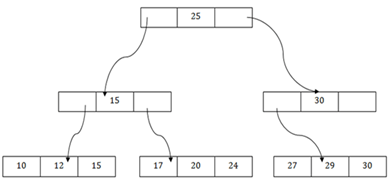
There is one root node of the tree, i.e., 25.
There is an intermediary layer with nodes. They do not store the actual record. They have only pointers to the leaf node.
The nodes to the left of the root node contain the prior value of the root and nodes to the right contain next value of the root, i.e., 15 and 30 respectively.
There is only one leaf node which has only values, i.e., 10, 12, 17, 20, 24, 27 and 29.
Searching for any record is easier as all the leaf nodes are balanced.
In this method, searching any record can be traversed through the single path and accessed easily.
In this method, searching becomes very easy as all the records are stored only in the leaf nodes and sorted the sequential linked list.
Traversing through the tree structure is easier and faster.
The size of the B+ tree has no restrictions, so the number of records can increase or decrease and the B+ tree structure can also grow or shrink.
It is a balanced tree structure, and any insert/update/delete does not affect the performance of tree.
(c) What is the difference between Join and Sub query? Explain any two built-in function for following category. 1) Numeric 2) String 3) Date
The Difference between Join and Sub query is that A join statment will join two or more tables together by a field related to both tables (ie, relationship of primary and foreign keys). It is typically easy to understand whereas A subquery statement involves a SELECT statement that selects particular values from a table. The values that the select query selects is dependant upon the subquery. The subquery itself is another SELECT statement.
Built-in Functions :
- 1. Numeric
ABS – Returns the absolute value of a number.
SELECTABS(-7+5)ASResult
SUM – Returns the sum of all the values or only the distinct values, in the expression. NULL values are ignored.
SELECTSUM(SALARY)FROMEmployee;
- 2. String
LOWER – Converts a string to lower case.
SELECT LOWER(CustomerName) AS LowercaseCustomerName
FROM Customers;SUBSTRING – Returns part of a character, binary, text, or image expression.
SELECT SUBSTRING(CustomerName, 1, 5) AS ExtractString
FROM Customers;- 3. Date
ISDATE – Determines whether the input is a valid date, time or datetime value.
SELECT ISDATE('2017-08-25');SELECT ISDATE('2017');DAY – Returns the Day as an integer representing the Day part of a specified date.
SELECT DAY('2017/08/25') AS DayOfMonth;Question: 4
(a) What is the view? How does it different from the table?
The view is a virtual/logical table formed as a result of a query and used to view or manipulate parts of the table. We can create the columns of the view from one or more tables. Its content is based on base tables.
The view is a database object with no values and contains rows and columns the same as real tables. It does not occupy space on our systems.
- The following points explain the differences between tables and views:
A table is a database object that holds information used in applications and reports. On the other hand, a view is also a database object utilized as a table and can also link to other tables.
A table consists of rows and columns to store and organized data in a structured format, while the view is a result set of SQL statements.
A table is structured with columns and rows, while a view is a virtual table extracted from a database.
The table is an independent data object while views are usually depending on the table.
The table is an actual or real table that exists in physical locations. On the other hand, views are the virtual or logical tablethat does not exist in any physical location.
A table allows to performs add, update or delete operations on the stored data. On the other hand, we cannot perform add, update, or delete operations on any data from a view. If we want to make any changes in a view, we need to update the data in the source tables.
We cannot replace the table object directly because it is stored as a physical entry. In contrast, we can easily use the replace option to recreate the view because it is a pseudo name to the SQL statement running behind on the database server.
(b) Explain below mentioned features of concurrency. 1) Improved throughput 2) Reduced waiting time
- Improved Throughput :
A transaction consists of many steps. Some involve I/O activity; others involve CPU activity. The CPU and the disks in a computer system can operate in parallel. Therefore, I/O activity can be done in parallel with processing at the CPU.
The parallelism of the CPU and the I/O system can therefore be exploited to run multiple transactions in parallel.
While a read or write on behalf of one transaction is in progress on one disk, another transaction can be running in the CPU, while another disk may be executing a read or write on behalf of a third transaction.
All of this increases the throughput of the system—that is, the number of transactions executed in a given amount of time.
Correspondingly, the processor and disk utilization also increase; in other words, the processor and disk spend less time idle, or not performing any useful work.
- Reduced waiting time :
There may be a mix of transactions running on a system, some short and some long.
If transactions run serially, a short transaction may have to wait for a preceding long transaction to complete, which can lead to unpredictable delays in running a transaction.
If the transactions are operating on different parts of the database, it is better to let them run concurrently, sharing the CPU cycles and disk accesses among them.
Concurrent execution reduces the unpredictable delays in running transactions.
Moreover, it also reduces the average response time: the average time for a transaction to be completed after it has been submitted.
(c) What is index in the database? Explain sparse indices and Dense indices with proper example.
indexing is used to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed.
The index is a type of data structure. It is used to locate and access the data in a database table quickly.
Indexes can be created using some database columns.

The first column of the database is the search key that contains a copy of the primary key or candidate key of the table. The values of the primary key are stored in sorted order so that the corresponding data can be accessed easily.
The second column of the database is the data reference. It contains a set of pointers holding the address of the disk block where the value of the particular key can be found.
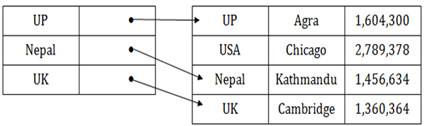
- Sparse indices :
In the data file, index record appears only for a few items. Each item points to a block.
In this, instead of pointing to each record in the main table, the index points to the records in the main table in a gap.
- Dense Indices :
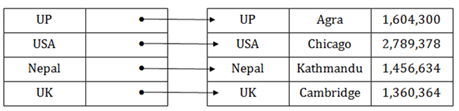
The dense index contains an index record for every search key value in the data file. It makes searching faster.
In this, the number of records in the index table is same as the number of records in the main table.
It needs more space to store index record itself. The index records have the search key and a pointer to the actual record on the disk.
Question: 4
(a) Differentiate dynamic hashing and static hashing.
| Dynamic Hashing | Static Hashing |
|---|---|
| Hash table size can change during execution | Hash table size is fixed at compile time or initialization |
| Used when the number of keys is unknown or may change | Used when the number of keys is known and will not change |
| Can use open addressing or chaining to resolve collisions | Typically uses chaining to resolve collisions |
| Insertions and deletions may require rehashing and resizing the table | Insertions and deletions do not require rehashing or resizing the table |
| Can use more memory than static hashing | Uses less memory than dynamic hashing |
(b) What is the atomicity and consistency property of transaction?
- Atomicity :
By this, we mean that either the entire transaction takes place at once or doesn’t happen at all. There is no midway i.e. transactions do not occur partially. Each transaction is considered as one unit and either runs to completion or is not executed at all. It involves the following two operations.
–Abort: If a transaction aborts, changes made to the database are not visible.
–Commit: If a transaction commits, changes made are visible.
Atomicity is also known as the ‘All or nothing rule’.
Consider the following transaction T consisting of T1 and T2: Transfer of 100 from account X to account Y.
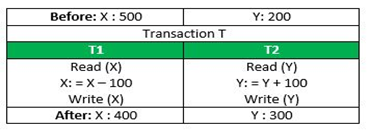
If the transaction fails after completion of T1 but before completion of T2.( say, after write(X) but before write(Y)), then the amount has been deducted from X but not added to Y. This results in an inconsistent database state. Therefore, the transaction must be executed in its entirety in order to ensure the correctness of the database state.
- Consistency :
This means that integrity constraints must be maintained so that the database is consistent before and after the transaction. It refers to the correctness of a database. Referring to the example above,
The total amount before and after the transaction must be maintained.
Total before T occurs = 500 + 200 = 700.
Total after T occurs = 400 + 300 = 700.
Therefore, the database is consistent. Inconsistency occurs in case T1 completes but T2 fails. As a result, T is incomplete.
(c) What is Query processing? Explain why ‘Parsing and translation’ and ‘Optimization’ steps are required for query processing.
Query Processing includes translations on high level Queries into low level expressions that can be used at physical level of file system, query optimization and actual execution of query to get the actual result.
Block Diagram of Query Processing is as:
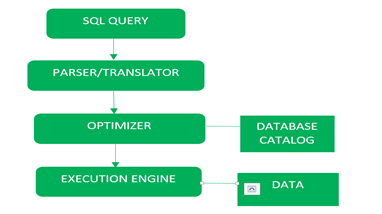
- Parsing & Translation
Parser/translator: During parse call, the database performs the following checks- Syntax check, Semantic check and Shared pool check, after converting the query into relational algebra.
Parser performs the following:
– Syntax check – concludes SQL syntactic validity. Example:
SELECT * FORM employee
Here error of wrong spelling of FROM is given by this check.
– Semantic check – determines whether the statement is meaningful or not. Example: query contains a tablename which does not exist is checked by this check.
– Shared Pool check – Every query possess a hash code during its execution. So, this check determines existence of written hash code in shared pool if code exists in shared pool then database will not take additional steps for optimization and execution.
Hard Parse and Soft Parse –
If there is a fresh query and its hash code does not exist in shared pool then that query has to pass through from the additional steps known as hard parsing otherwise if hash code exists then query does not passes through additional steps. It just passes directly to execution engine (refer detailed diagram). This is known as soft parsing.
Hard Parse includes following steps – Optimizer and Row source generation.
- Optimization
Optimizer: During optimization stage, database must perform a hard parse atleast for one unique DML statement and perform optimization during this parse. This database never optimizes DDL unless it includes a DML component such as subquery that require optimization.
It is a process in which multiple query execution plan for satisfying a query are examined and most efficient query plan is satisfied for execution.
Database catalog stores the execution plans and then optimizer passes the lowest cost plan for execution.
Row Source Generation –The Row Source Generation is a software that receives a optimal execution plan from the optimizer and produces an iterative execution plan that is usable by the rest of the database. the iterative plan is the binary program that when executes by the sql engine produces the result set.
Question: 5
(a) How does ‘partial commit’ state differ from ‘commit’ state of the transaction?
In a database management system, a transaction is a sequence of operations that are treated as a single unit of work. The two main states of a transaction are the “partial commit” state and the “commit” state.
- Partial Commit State: In the partial commit state, some of the changes made by the transaction are saved to the database, while the remaining changes are still in the transaction buffer and have not yet been written to the database. In this state, the transaction can still be rolled back if there is a failure, and the database can be restored to its original state before the transaction started.
- Commit State: In the commit state, all the changes made by the transaction are saved to the database, and the transaction is completed. Once the transaction has been committed, it cannot be rolled back, and the changes made by the transaction become permanent in the database.
The main difference between the partial commit state and the commit state is that in the partial commit state, only some of the changes made by the transaction are saved to the database, while in the commit state, all the changes made by the transaction are saved to the database. The partial commit state is useful in situations where a transaction involves multiple steps, and it is not necessary to commit all the changes at once. For example, in a banking application, a transaction that involves transferring money from one account to another may involve multiple steps, such as checking the account balance, deducting the amount from the source account, and adding the amount to the destination account. In this case, the partial commit state can be used to save the changes made in each step before committing the entire transaction. This can help in reducing the risk of errors and ensuring data consistency in the database.
(b) Enlist and explain user authorization to modify the database schema.
Authorization is finding out if the person once identified, is permitted to have the resource.
Authorization explains that what you can do and is handled through the DBMS unless external security procedures are available.
This is usually determined by finding out if that person is a part of a particular group, if that person has paid admission, or has a particular level of security clearance.
Authorization is equivalent to checking the guest list at an exclusive party or checking a ticket in an opera.
DBMS allows DBA to give different access rights to the users as per their requirement.
In SQL Authorization can be done by using Read, Insert, Update or Delete privileges.
Types of authorization: We can use any one or combinations of the following basic forms of authorization.
a) Resource Authorization:
Authorization to access any system resource
E.g: Sharing of database, Printers.
b) Alternation Authorization:
Authorization to add attributes or delete attributes from relations.
c) Drop Authorization:
Authorization to drop a relation.
(c) How does two phase locking protocol differ from timestamp based protocol? Explain timestamp-ordering protocol.
Two-phase locking:- In databases and transaction processing, two-phase locking is a concurrency control method that guarantees serializability. It is also the name of the resulting set of database transaction schedules. The protocol utilizes locks, applied by a transaction to data, which may block other transactions from accessing the same data during the transaction’s life.
Timestamp-based Protocols:- The most commonly used concurrency protocol is the timestamp based protocol. This protocol uses either system time or logical counter as a timestamp.
Lock-based protocols manage the order between the conflicting pairs among transactions at the time of execution, whereas timestamp-based protocols start working as soon as a transaction is created.
Every transaction has a timestamp associated with it, and the ordering is determined by the age of the transaction. A transaction created at 0002 clock time would be older than all other transactions that come after it. For example, any transaction ‘y’ entering the system at 0004 is two seconds younger and the priority would be given to the older one.
In addition, every data item is given the latest read and write-timestamp. This lets the system know when the last ‘read and write’ operation was performed on the data item.
- Timestamp Ordering Protocol
The Timestamp Ordering Protocol is used to order the transactions based on their Timestamps. The order of transaction is nothing but the ascending order of the transaction creation.
The priority of the older transaction is higher that’s why it executes first. To determine the timestamp of the transaction, this protocol uses system time or logical counter.
The lock-based protocol is used to manage the order between conflicting pairs among transactions at the execution time. But Timestamp based protocols start working as soon as a transaction is created.
Let’s assume there are two transactions T1 and T2. Suppose the transaction T1 has entered the system at 007 times and transaction T2 has entered the system at 009 times. T1 has the higher priority, so it executes first as it is entered the system first.
The timestamp ordering protocol also maintains the timestamp of last ‘read’ and ‘write’ operation on a data.
Basic Timestamp ordering protocol works as follows:
1. Check the following condition whenever a transaction Ti issues a Read (X) operation:
- If W_TS(X) >TS(Ti) then the operation is rejected.
- If W_TS(X) <= TS(Ti) then the operation is executed.
- Timestamps of all the data items are updated.
2. Check the following condition whenever a transaction Ti issues a Write(X) operation:
- If TS(Ti) < R_TS(X) then the operation is rejected.
- If TS(Ti) < W_TS(X) then the operation is rejected and Ti is rolled back otherwise the operation is executed.
Where,Triggers in SQL (Hindi)
TS(TI) denotes the timestamp of the transaction Ti.
R_TS(X) denotes the Read time-stamp of data-item X.
W_TS(X) denotes the Write time-stamp of data-item X.
TO protocol ensures serializability since the precedence graph is as follows:
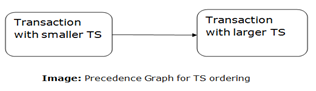
TS protocol ensures freedom from deadlock that means no transaction ever waits. But the schedule may not be recoverable and may not even be cascade- free.
Question: 5
(a) Why does the trigger require in database? Write SQL syntax for creating database trigger.
Triggers are used for several purposes:
Produce additional checking during insert, update or delete operations on the affected table.
They allow us to encode complex default values that cannot be handled by default constraints.
Implement referential integrity across databases.
They allow us to control what actually happens when one performs an insert, update, or delete on a view that accesses multiple tables.
You can calculate aggregated columns in a table using triggers.
A trigger is a stored procedure in database which automatically invokes whenever a special event in the database occurs. For example, a trigger can be invoked when a row is inserted into a specified table or when certain table columns are being updated.
Syntax:
create trigger [trigger_name]
[before | after]
{insert | update | delete}
on [table_name]
[for each row]
[trigger_body]
Example :
create trigger stud_marks
before INSERT
on
Student
for each row
set Student.total = Student.subj1 + Student.subj2 + Student.subj3, Student.per = Student.total * 60 / 100;
(b) When do we require to use group by clause? How aggregate functions are used with group by clause?
The Group By statement is used to group together any rows of a column with the same value stored in them, based on a function specified in the statement. Generally, these functions are one of the aggregate functions such as MAX() and SUM().
Aggregate functions are used in place of column names in the SELECT statement.
the four aggregate functions that we can use with the SQL Order By statement are:
– AVG(): Calculates the average of the set of values.
SELECT Dept_ID, AVG(Salary) FROM Employee_ dept GROUP BY Dept_ID;– COUNT(): Returns the count of rows.
SELECT City, COUNT (City) FROM Employee_dept GROUP BY City ORDER BY COUNT (City);– SUM(): Calculates the arithmetic sum of the set of numeric values.
SELECT COUNT (Dept ID), SUM(Salary) FROM Employee dept:– MAX(): From a group of values, returns the maximum value.
SELECT Dept_ID, MAX(Salary)
FROM Employee_dept WHERE Dept ID>1003 GROUP BY Dept_ID;(c) When Join is used in SQL? Explain Left outer, Right outer and Full outer join with SQL syntax.
SQL joins are used to combine data from two or more tables. Basic joins used are FULL, INNER, RIGHT, LEFT, and CROSS Joins.
Any join query in SQL will require more than one table, and there will be a need for the association to link the results from table “A” to table “B”. So, joins are used in SQL Queries to fetch data from two different tables at the same time.
- Left Outer Join :
Left Outer Join returns all the rows from the table on the left and columns of the table on the right is null padded. Left Outer Join retrieves all the rows from both the tables that satisfy the join condition along with the unmatched rows of the left table.
Syntax:
SELECT [column1, column2, ....]
FROM table1
LEFT OUTER JOIN table2 ON
table1.matching_column = table2.matching_column
WHERE [condition]; - Right Outer Join:
Right Outer Join returns all the rows from the table on the right and columns of the table on the left is null padded. Right Outer Join retrieves all the rows from both the tables that satisfy the join condition along with the unmatched rows of the right table.
Syntax:
SELECT [column1, column2, ....]
FROM table1
RIGHT OUTER JOIN table2 ON
table1.matching_column = table2.matching_column
WHERE [condition];- Full Outer Join:
Full Outer Join returns all the rows from both the table. When no matching rows exist for the row in the left table, the columns of the right table are null padded. Similarly, when no matching rows exist for the row in the right table, the columns of the left table are null padded. Full outer join is the union of left outer join and right outer join.
Syntax:
SELECT [column1, column2, ....]
FROM table1
FULL OUTER JOIN table2
ON table1.matching_column = table2.matching_column
WHERE [condition];Read More : DS GTU Paper Solution Winter 2021
Read More : DBMS GTU Paper Solution Winter 2020
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.
Read, DBMS Winter 2020 Paper Solution