Here, We provide OS GTU Paper Solution Summer 2022. Read the Full OS GTU paper solution given below.
Operating System Old Paper Winter 2022 [Marks : 70] : Click Here
(a) List any four functions of the operating system?
Operating systems provide a wide range of functions to manage and control the resources of a computer system. Here are four important functions of an operating system:
- Process Management: The operating system manages the creation, execution, and termination of processes. It provides mechanisms for process scheduling, synchronization, communication, and resource allocation. The process management function is essential for the efficient and reliable operation of the system.
- Memory Management: The operating system manages the allocation and deallocation of memory to processes. It provides mechanisms for virtual memory, paging, segmentation, and memory protection. The memory management function is critical for the efficient use of system resources and the prevention of memory-related errors.
- File Management: The operating system manages the creation, deletion, and manipulation of files and directories. It provides mechanisms for file organization, access control, and backup. The file management function is essential for data storage, retrieval, and protection.
- Device Management: The operating system manages the communication between the computer system and the various devices connected to it, such as printers, disks, and network interfaces. It provides mechanisms for device drivers, interrupts handling, and input/output operations. The device management function is critical for the proper functioning of the system and the efficient use of devices.
(b) Explain the essential properties of
i) Batch system ii) Time sharing
iii) Real time iv) Distribute
i) Batch System: A batch system is a type of operating system that processes a large number of similar jobs in batches, without any user interaction. The essential properties of a batch system include:
- Non-interactive
- Queueing
- No immediate user feedback
- No time-sharing
ii) Time Sharing: Time-sharing is a type of operating system that allows multiple users to access the system simultaneously by sharing the CPU time. The essential properties of a time-sharing system include:
- Interactive
- CPU time-sharing
- Fast response time
- Resource sharing
- User convenience
iii) Real-time: Real-time operating systems are designed to respond to events in real-time, i.e., within a predetermined time frame. The essential properties of a real-time system include:
- Determinism
- Priority-based scheduling
- Predictability
- Reliability
- Minimal latency
iv) Distributed: A distributed operating system is a system that manages resources across a network of interconnected computers. The essential properties of a distributed system include:
- Resource sharing
- Transparency
- Fault tolerance
- Scalability
- Heterogeneity
(c) Explain process states and process control blocks in detail.
Process States: A process is an instance of a program in execution. Process states represent the various stages through which a process passes during its lifetime. The process states can vary depending on the operating system, but generally, they include the following:
- New: The process is being created, and its initial resources are being allocated.
- Ready: The process is waiting to be assigned the CPU for execution.
- Running: The process is currently executing on the CPU.
- Waiting: The process is waiting for some event to occur, such as input/output completion or a signal from another process.
- Terminated: The process has completed its execution and has been terminated.
Process Control Block (PCB): The Process Control Block (PCB) is a data structure used by the operating system to manage the execution of a process. It contains all the information needed by the operating system to manage the process, including:
- Process ID: A unique identifier assigned to each process.
- Process state: The current state of the process.
- CPU registers: The contents of the CPU registers when the process was last executed.
- Memory management information: Information about the memory allocation of the process, such as the memory size, location, and page table.
- Input/output status information: Information about any input/output operations that the process is currently waiting for, such as device numbers and the location of input/output buffers.
- Scheduling information: Information about the process priority, scheduling algorithm, and any other scheduling parameters.
- Accounting information: Information about the resources used by the process, such as CPU time, memory usage, and disk usage.
The operating system uses the PCB to manage the execution of a process. When a process is interrupted or switches to a different state, the operating system saves the relevant information in the PCB. When the process resumes its execution, the operating system restores the saved information from the PCB. The PCB plays a critical role in process management, allowing the operating system to manage the execution of multiple processes concurrently while maintaining their state information.
(a) What are the various criteria for a good process scheduling algorithm?
A process scheduling algorithm is a key component of an operating system, responsible for determining which process should be assigned to the CPU at a given time. The effectiveness of a scheduling algorithm can have a significant impact on the overall performance of the system. The following are the various criteria for a good process scheduling algorithm:
- Fairness: A good scheduling algorithm should ensure that all processes are treated fairly, giving each process an equal chance to access the CPU and other system resources.
- Efficiency: A good scheduling algorithm should be efficient in terms of CPU utilization, minimizing the amount of time that the CPU is idle and maximizing the throughput of the system.
- Responsiveness: A good scheduling algorithm should be responsive to user requests, allowing interactive processes to have a high priority and a fast response time.
- Predictability: A good scheduling algorithm should be predictable in terms of the amount of time required for a process to complete its execution, minimizing variations in response time and ensuring that processes complete within a reasonable time frame.
- Prioritization: A good scheduling algorithm should allow processes to be prioritized based on their importance or urgency, ensuring that critical processes are given a higher priority than less important processes.
- Balancing: A good scheduling algorithm should balance the load on the system, distributing the CPU time and other resources evenly among the processes to avoid overloading some processes while others are idle.
- Adaptability: A good scheduling algorithm should be adaptable to different workloads and system configurations, adjusting its behavior based on the system’s changing conditions and requirements.
(b) What is a thread? Explain the classical thread model.
A thread is a lightweight process that can be executed independently within a process. A thread shares the same memory space and system resources as other threads within the same process. Threads are used to perform concurrent operations within a single process, allowing multiple tasks to be executed simultaneously.
The classical thread model, also known as the user-level thread model, is a thread model that is implemented entirely in user space, without any support from the operating system kernel. In this model, threads are created, scheduled, and managed by a user-level library rather than the operating system.
In the classical thread model, each thread maintains its own thread context, including the program counter, CPU registers, and stack. The thread context is saved and restored by the thread library when a thread is switched in or out of the CPU.
The thread library provides the following functions for managing threads:
- Thread creation: A new thread is created by calling the thread library function, which allocates a new thread context and stack space for the thread.
- Thread scheduling: The thread library determines which thread should be executed next based on a scheduling algorithm, and then saves the context of the currently executing thread and restores the context of the next thread to be executed.
- Thread synchronization: The thread library provides synchronization mechanisms such as locks, semaphores, and condition variables to allow threads to coordinate their activities and avoid race conditions.
- Thread termination: A thread can be terminated by calling the thread library function, which releases the resources associated with the thread and removes it from the list of active threads.
The classical thread model is efficient because thread switching can be done entirely in user space without the overhead of a system call. However, it also has some drawbacks, including a lack of support for kernel-level synchronization primitives and a potential for thread starvation if the thread library’s scheduling algorithm is not properly designed.
(c) How semaphores can be used to deal with the n-process critical section
problem? Explain.
Semaphores can be used to solve the n-process critical section problem, which occurs when multiple processes or threads are trying to access a shared resource or critical section simultaneously. The goal of the problem is to ensure that only one process is allowed to enter the critical section at a time, while the other processes are blocked.
A semaphore is a synchronization primitive that can be used to coordinate access to shared resources. It consists of a value and two atomic operations: wait and signal. The wait operation decrements the value of the semaphore and blocks the calling process if the value becomes negative. The signal operation increments the value of the semaphore and wakes up any blocked processes.
To solve the n-process critical section problem, we can use two semaphores: one to control access to the critical section and one to count the number of processes in the critical section.
When a process wants to enter the critical section, it first waits on the “access” semaphore. If the semaphore value is 0, the process blocks and waits for the semaphore to be signaled. When the semaphore is signaled, the process decrements the value of the “count” semaphore and enters the critical section.
While a process is in the critical section, the “access” semaphore remains locked, preventing other processes from entering. When the process is finished with the critical section, it increments the value of the “count” semaphore and signals the “access” semaphore to allow other processes to enter.
Here’s a sample pseudocode to illustrate the solution:
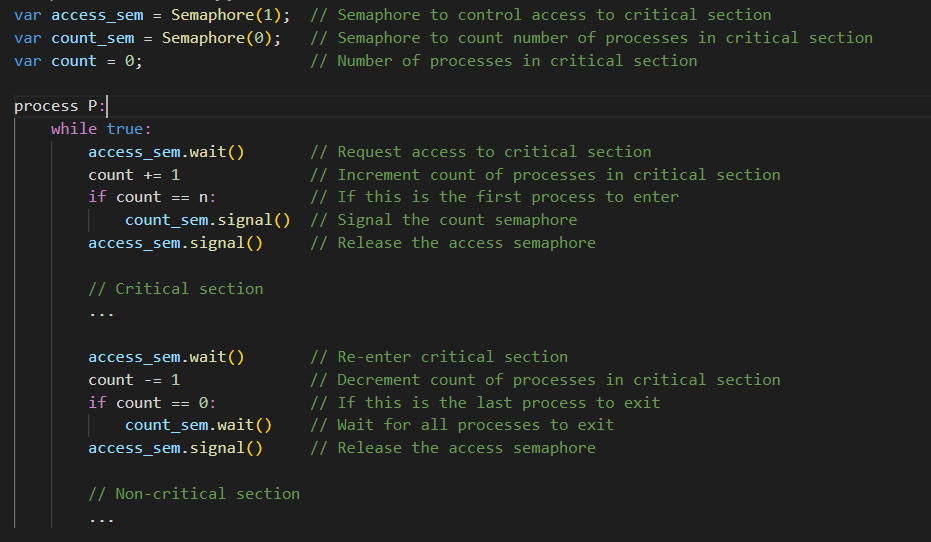
In this solution, each process waits for the “access” semaphore before entering the critical section, and increments the “count” semaphore to indicate that it is in the critical section. When a process is finished with the critical section, it decrements the “count” semaphore and signals the “access” semaphore to allow other processes to enter. The “count” semaphore is used to ensure that all processes have exited the critical section before allowing another process to enter.
By using semaphores to control access to the critical section and count the number of processes in the critical section, we can ensure that only one process is allowed to enter the critical section at a time while the other processes are blocked.
(c) What is the monitor? Explain the solution for the producer-consumer problem using
the monitor.
A monitor is a synchronization construct that allows multiple threads to access a shared resource in a mutually exclusive way. It consists of a set of procedures, variables, and data structures that can be accessed by multiple threads, but only one thread can be executed inside the monitor at any given time. The purpose of a monitor is to provide a higher level of abstraction for synchronization, making it easier to write correct concurrent programs.
The producer-consumer problem is a classic synchronization problem in which one or more producer threads generate data items and put them into a shared buffer, while one or more consumer threads remove the data items from the buffer and process them. The problem is to ensure that producers and consumers do not access the buffer at the same time, which can lead to race conditions and data corruption.
One solution to the producer-consumer problem is to use a monitor. Here’s how it works:
- Define a monitor that contains the shared buffer and the variables and procedures needed to synchronize access to the buffer.
- Define two procedures, “put” and “get”, which allow producers and consumers to insert and remove data items from the buffer. These procedures are implemented inside the monitor and use synchronization primitives such as semaphores or mutexes to ensure mutual exclusion.
- When a producer wants to put a data item into the buffer, it calls the “put” procedure inside the monitor. If the buffer is full, the producer waits on a “buffer not full” condition variable inside the monitor until space becomes available.
- When a consumer wants to get a data item from the buffer, it calls the “get” procedure inside the monitor. If the buffer is empty, the consumer waits on a “buffer not empty” condition variable inside the monitor until a data item becomes available.
- When a producer inserts a data item into the buffer, it signals the “buffer not empty” condition variable to wake up any waiting consumers.
- When a consumer removes a data item from the buffer, it signals the “buffer, not full” condition variable to wake up any waiting producers.
(a) Define preemption and nonpreemption.
In operating systems, preemption and non-preemption refer to two different approaches to process scheduling.
Preemption is the ability of an operating system to forcibly interrupt a running process and move it to a waiting state, so that another process can be executed. Preemption can occur either voluntarily or involuntarily. Voluntary preemption occurs when a process yields the CPU to allow another process to run, while involuntary preemption occurs when a process is interrupted by the operating system due to higher priority processes waiting to be executed.
Non-preemption, on the other hand, is a scheduling policy that does not allow a running process to be interrupted before it completes its execution. In non-preemptive scheduling, a process continues to run until it voluntarily relinquishes the CPU or until it completes its execution.
The choice between preemption and non-preemption depends on the requirements of the system and the nature of the tasks being performed. Preemption is often used in real-time systems or in situations where a process must be interrupted to respond to an event or input. Non-preemption is often used in systems that require a predictable and deterministic behavior, where each process can be guaranteed a minimum amount of CPU time without being interrupted.
(b)Explain the terms related to IPC:
i) Race condition ii) Critical section iii) Mutual exclusion iv) Semaphores
Inter-Process Communication (IPC) is an important concept in operating systems that allows different processes to share data and communicate with each other. There are several terms related to IPC, including:
- Race condition: A race condition is a situation where two or more processes or threads try to access a shared resource or variable simultaneously, leading to unpredictable or incorrect behavior. In other words, the outcome of the operation depends on the sequence or timing of events, and different runs of the same program may produce different results.
- Critical section: A critical section is a portion of code in a program where a shared resource or variable is accessed or modified. Since multiple processes or threads can access the critical section simultaneously, it is important to ensure that only one process can access the critical section at a time to avoid race conditions.
- Mutual exclusion: Mutual exclusion is a mechanism that ensures that only one process or thread can access a shared resource or critical section at a time. It is used to prevent race conditions and guarantee consistency and correctness of the shared data.
- Semaphores: A semaphore is a synchronization object that is used to implement mutual exclusion and coordinate access to shared resources. A semaphore maintains a count that can be incremented or decremented by processes, and it provides two operations: wait and signal. The wait operation decrements the count and blocks the process if the count is zero, while the signal operation increments the count and wakes up any blocked processes if the count is positive. Semaphores can be binary or counting, and they are used to implement critical sections, solve synchronization problems, and prevent deadlock and livelock.
(c) How does deadlock avoidance differ from deadlock prevention? Write about
deadlock avoidance algorithm in detail.
Deadlock is a situation in operating systems where two or more processes are unable to proceed because each is waiting for the other to release a resource. Deadlocks can occur in systems that use multiple resources, such as shared memory, files, or devices, and they can cause system-wide delays and even crashes. There are two main approaches to dealing with deadlocks in operating systems: deadlock prevention and deadlock avoidance.
Deadlock prevention involves designing the system in such a way that deadlocks cannot occur. This can be achieved by using techniques such as resource allocation graphs, banker’s algorithm, or limiting resource requests. Deadlock prevention is usually a more rigid approach and requires a detailed understanding of the system and its requirements.
Deadlock avoidance, on the other hand, is a more flexible approach that allows deadlocks to be avoided dynamically at runtime. The basic idea behind deadlock avoidance is to allocate resources to processes in a way that avoids the possibility of a deadlock. To achieve this, the system must have information about the current state of the system, including the available resources, the current allocation of resources, and the future resource requests of processes.
One commonly used deadlock avoidance algorithm is the Banker’s algorithm, which is a resource allocation and deadlock avoidance algorithm. The Banker’s algorithm uses a set of data structures to keep track of the available resources, the current allocation of resources, and the future resource requests of processes. The algorithm works by simulating the allocation of resources to each process and checking whether this will lead to a safe state, i.e., a state in which no deadlocks can occur.
In the Banker’s algorithm, the system maintains a matrix that represents the available resources, a matrix that represents the current allocation of resources to each process, and a matrix that represents the future resource requests of each process. Based on this information, the algorithm performs a series of tests to determine whether a resource request can be granted without leading to a deadlock.
The Banker’s algorithm works as follows:
- When a process requests a resource, the system checks whether the request can be granted without leading to a deadlock.
- If the request can be granted, the system updates the allocation matrix and the available resources matrix accordingly and proceeds with the request.
- If the request cannot be granted, the system denies the request and waits until the requested resource becomes available.
- When a process releases a resource, the system updates the allocation matrix and the available resources matrix accordingly and checks whether this has resolved any deadlocks.
- If a deadlock is detected, the system uses a recovery algorithm to resolve the deadlock by releasing some resources or killing some processes.
The Banker’s algorithm is a well-known and widely used algorithm for deadlock avoidance. It provides a way to allocate resources to processes in a safe and efficient way, while preventing deadlocks from occurring. However, it requires a lot of system resources and can be complex to implement, making it less suitable for some applications.
(a) Give the Difference between Thread and Process.
In computing, a thread and a process are two different execution models that are used to run programs on a computer. The main differences between threads and processes are:
- Definition: A process is an instance of a program that is running on a computer, while a thread is a smaller unit of execution within a process. In other words, a process can contain multiple threads.
- Memory: Each process has its own memory space, while threads within a process share the same memory space. This means that threads can share data and resources, which can make them more efficient than separate processes.
- Creation and destruction: Processes are typically created and destroyed by the operating system, while threads are created and destroyed by the parent process.
- Communication and synchronization: Processes use inter-process communication (IPC) mechanisms such as pipes, message queues, and shared memory to communicate with each other. Threads, on the other hand, can communicate with each other directly through shared memory and synchronization mechanisms such as locks, semaphores, and condition variables.
- Resource usage: Each process has its own system resources such as file descriptors, sockets, and environment variables. Threads, on the other hand, share the same system resources as the parent process.
- CPU utilization: Since threads share the same memory space and system resources, they can be more efficient in terms of CPU utilization than separate processes.
- Security: Each process runs in its own memory space and is protected from other processes. Threads, on the other hand, share the same memory space and are less secure than separate processes.
In summary, a process is a self-contained program that runs on a computer, while a thread is a smaller unit of execution within a process. Processes are typically created and destroyed by the operating system, while threads are created and destroyed by the parent process. Processes have their own memory space and system resources, while threads share the same memory space and system resources as the parent process. Processes communicate with each other through IPC mechanisms, while threads can communicate with each other directly through shared memory and synchronization mechanisms.
(b) Explain the Priority scheduling algorithm.
Priority scheduling is a CPU scheduling algorithm in which each process is assigned a priority and the CPU is allocated to the process with the highest priority. The priority of a process is determined based on factors such as the amount of time the process has been waiting, the amount of resources it requires, and its importance to the system.
The basic idea of priority scheduling is to ensure that the most important processes are given the highest priority and are executed first. This can help to improve system performance by ensuring that important processes are completed quickly, while lower-priority processes are put on hold.
There are two types of priority scheduling algorithms:
- Non-preemptive Priority Scheduling: In this algorithm, a process that is currently running will continue to run until it completes or is blocked by an I/O operation. Only when the process is blocked or completes, the next process with the highest priority will be selected to run.
- Preemptive Priority Scheduling: In this algorithm, a process that is currently running can be preempted if a higher priority process becomes available. The process that is preempted will be put back in the ready queue and will be executed later.
One disadvantage of priority scheduling is that it can lead to starvation, where low-priority processes are continually put on hold in favor of high-priority processes. To avoid starvation, some priority scheduling algorithms use aging, which gradually increases the priority of a process as it waits in the ready queue.
Overall, priority scheduling can be an effective way to allocate CPU resources to the most important processes, but it must be used carefully to avoid starvation and ensure that lower-priority processes are eventually executed.
(c) How to characterize the structure of deadlock? Explain the two solutions of
recovery from deadlock.
The structure of deadlock can be characterized by four conditions known as the Coffman conditions:
- Mutual exclusion: Resources that are being held by a process cannot be shared with other processes. This means that only one process can have exclusive access to a resource at a time.
- Hold and wait: A process that is holding a resource can request additional resources while still holding the current resource. This creates a situation where a process is waiting for resources to become available, which may be held by other processes.
- No preemption: Resources cannot be forcibly removed from a process that is holding them. This means that a process can only release a resource voluntarily.
- Circular wait: A circular chain of processes exists, where each process is waiting for a resource that is being held by another process in the chain.
There are two main solutions for recovering from deadlock:
- Deadlock prevention: This involves structuring the system in such a way that one or more of the Coffman conditions are not satisfied. For example, mutual exclusion can be eliminated by allowing multiple processes to share the same resource. Hold and wait can be eliminated by requiring a process to request all the resources it needs before it can start executing. No preemption can be eliminated by allowing resources to be forcibly removed from a process. Circular wait can be eliminated by assigning a unique priority to each resource and requiring that resources are requested in a specific order.
- Deadlock avoidance: This involves dynamically assessing the system state to determine whether a particular resource allocation will result in deadlock. This can be done using algorithms such as the banker’s algorithm, which involves simulating all possible resource allocation scenarios to determine whether deadlock will occur. If a resource allocation will result in deadlock, it can be avoided by denying the request or delaying it until the resource becomes available.
Both deadlock prevention and avoidance have their advantages and disadvantages. Deadlock prevention is more reliable but can be difficult to implement, while deadlock avoidance is more flexible but can be computationally expensive. Ultimately, the choice between the two solutions depends on the specific requirements and constraints of the system being developed.
(a) List out the seven RAID levels.
The seven RAID (Redundant Array of Independent Disks) levels are:
- RAID 0: This level uses disk striping without any redundancy. It provides improved performance by spreading data across multiple disks, but does not offer any data protection.
- RAID 1: This level uses disk mirroring to create an exact copy of data on two disks. It provides excellent data protection, but is expensive since it requires twice the amount of storage capacity.
- RAID 2: This level uses disk striping with error correction code (ECC) to detect and correct errors in data. It is not widely used in practice.
- RAID 3: This level uses byte-level striping with a dedicated parity disk. It provides good data protection and high read performance, but poor write performance.
- RAID 4: This level uses block-level striping with a dedicated parity disk. It provides good data protection and high read performance, but poor write performance.
- RAID 5: This level uses block-level striping with distributed parity. It provides good data protection and high read and write performance, but requires a minimum of three disks.
- RAID 6: This level uses block-level striping with double distributed parity. It provides even better data protection than RAID 5 by allowing for the failure of two disks, but requires a minimum of four disks.
Each RAID level has its own strengths and weaknesses, and the choice of which level to use depends on the specific requirements of the system being developed.
(b) Write a short note on the Relocation problem for multiprogramming with fixed
partitions.
In multiprogramming with fixed partitions, the main memory is divided into fixed-size partitions, and each partition is allocated to a specific process. When a process is loaded into memory, it is loaded into its assigned partition. However, this approach presents a problem known as the relocation problem.
The relocation problem arises when a process needs more memory than is available in its assigned partition. For example, if a process is assigned a 1 MB partition but requires 2 MB of memory, it cannot be loaded into memory. This can result in fragmentation of memory, where small unused gaps are created between allocated partitions, reducing the amount of available memory.
One solution to the relocation problem is to use dynamic memory allocation, where memory is allocated to a process as needed. This requires the use of a memory manager to keep track of which memory locations are in use and which are free.
Another solution is to use overlay techniques, where the process is divided into smaller sections, or overlays, that can be loaded into memory as needed. Only the overlay that is currently being used by the process is kept in memory, while the others are kept on disk. This approach requires careful management of memory, as well as the ability to switch between overlays quickly and efficiently.
In summary, the relocation problem is a challenge in multiprogramming with fixed partitions, where the size of the memory partition is fixed and cannot be changed. Dynamic memory allocation and overlay techniques are two possible solutions to this problem.
(c) What is paging? Discuss basic paging techniques in detail.
Paging is a memory management technique used in modern operating systems that allows a computer to store and retrieve data from secondary storage (usually a hard disk drive) as if it were primary memory (RAM). Paging is based on the idea of dividing memory into fixed-size blocks called pages and storing them in non-contiguous blocks in secondary storage.
The basic paging technique involves the following steps:
- Divide the logical memory into fixed-size blocks called pages. The size of each page is typically a power of two and is chosen to be small enough to minimize internal fragmentation but large enough to reduce the overhead of managing a large number of pages.
- Divide the physical memory into fixed-size blocks called frames. The size of each frame is the same as the size of a page.
- When a process requests memory, the operating system allocates a certain number of contiguous pages in logical memory to the process.
- The virtual address generated by the process is divided into two parts: the page number and the offset within the page.
- The page number is used to access the page table, which contains the base address of the corresponding frame in physical memory.
- The offset is added to the base address to obtain the physical memory address of the requested data.
- If the requested page is not present in physical memory, a page fault occurs and the operating system loads the required page from secondary storage into a free frame in physical memory.
- The page table is updated to reflect the new mapping between the page and the frame.
- If there are no free frames in physical memory, the operating system uses a page replacement algorithm to choose a victim page to be replaced with the new page.
The basic paging technique provides a number of benefits over other memory management techniques, such as dynamic partitioning. Paging allows for better memory utilization and reduces the amount of internal fragmentation by dividing memory into fixed-size pages. It also provides better memory protection by keeping each process in its own address space, which prevents one process from accessing or modifying the memory of another process.
(a) What is the difference between logical I/O and device I/O?
Logical I/O and device I/O are two types of input/output operations that occur in computer systems. The main difference between the two is the level of abstraction they operate at.
Logical I/O operates at a higher level of abstraction and involves interactions between the operating system and the application programs. It involves reading and writing data to and from logical devices such as files, pipes, and sockets. Logical I/O is managed by the operating system and abstracts away the underlying hardware details of the actual input/output devices.
Device I/O, on the other hand, operates at a lower level of abstraction and involves interactions between the device driver and the hardware device. It involves reading and writing data to and from physical devices such as hard disks, network cards, and printers. Device I/O is managed by the device driver and directly accesses the hardware device.
In other words, logical I/O refers to the input/output operations that applications use to interact with the operating system, while device I/O refers to the input/output operations that the operating system uses to interact with physical hardware devices.
(b) Write the first, best fit memory allocation techniques.
Memory allocation is a key aspect of memory management in operating systems, where the operating system must allocate memory to processes for their use. There are several memory allocation techniques, including first fit and best fit.
The first fit memory allocation technique involves allocating the first available block of memory that is large enough to fit the process’s memory requirements. The memory allocator starts at the beginning of the free memory space and searches for the first available block of memory that can fit the process’s memory requirements. Once the block is found, the memory allocator splits the block into two parts: one part is allocated to the process and the other part is returned to the free memory pool.
One advantage of the first fit memory allocation technique is that it is simple and efficient in terms of time complexity. However, it can lead to significant fragmentation of memory as small, unused gaps of memory are left between allocated blocks.
The best fit memory allocation technique involves allocating the smallest available block of memory that is large enough to fit the process’s memory requirements. The memory allocator searches the free memory pool for the block that best fits the process’s memory requirements. This technique ensures that the smallest gap is left between allocated blocks, thereby minimizing fragmentation of memory.
One disadvantage of the best fit memory allocation technique is that it can be slower and more complex than first fit because it requires searching the free memory pool for the best available block. Additionally, it can lead to inefficient use of memory as small gaps of unused memory may be left between allocated blocks.
(c) Define Virtual Memory. Explain the process of converting virtual addresses
to physical addresses with a neat diagram.
Virtual memory is a memory management technique used by operating systems to allow programs to use more memory than is physically available in the computer’s RAM. It uses the hard disk or solid-state drive (SSD) as an extension of RAM to temporarily store data that cannot fit in RAM.
The process of converting virtual addresses to physical addresses involves several steps. First, each process is assigned a unique virtual address space, which is divided into fixed-size pages. The size of each page is typically 4KB, although it can vary depending on the operating system.
When a program requests a piece of memory, it is allocated a contiguous block of virtual memory addresses. These virtual addresses are then translated into physical addresses, which refer to a specific location in physical memory, using a page table. The page table is a data structure maintained by the operating system that maps virtual addresses to physical addresses.
To convert a virtual address to a physical address, the page table is consulted. The page table contains an entry for each virtual page, which includes the physical address where the page is stored in memory. The page table also includes information about whether the page is present in memory or if it has been swapped out to the hard disk or SSD.
If the page is present in memory, the page table provides the physical address of the page, and the program can access the data directly from memory. If the page is not present in memory, a page fault occurs, and the operating system retrieves the page from the hard disk or SSD and loads it into memory. Once the page is loaded, the page table is updated with the physical address of the newly loaded page.
(a) Explain access control list.
An access control list (ACL) is a list of permissions that is associated with an object, such as a file or a directory. It determines which users or groups can access or modify the object and what actions they can perform on it.
An ACL is typically created and managed by the operating system or file system, and it is enforced by the system’s security subsystem. The ACL consists of one or more access control entries (ACEs), which define the permissions for individual users or groups.
Each ACE contains the following information:
- Security identifier (SID): A unique identifier for a user or group that is used to check permissions.
- Access mask: A set of flags that specify the types of access that are allowed or denied, such as read, write, or execute.
- Access type: Whether the ACE allows or denies access.
- Inheritance flags: Whether the ACE should be inherited by child objects.
(b) Differentiate between Windows and Linux file system.
Windows and Linux are two different operating systems with different file systems. Here are some of the key differences between the file systems used by Windows and Linux:
- File system structure: Windows uses the NTFS (New Technology File System) file system, while Linux typically uses the ext4 file system. NTFS supports features like file compression, encryption, and access control lists, while ext4 is designed to be more efficient and reliable for Linux file operations.
- Path separator: Windows uses backslashes () as path separators, while Linux uses forward slashes (/). This means that file paths in Windows look like C:\Users\UserName\Desktop\File.txt, while in Linux they look like /home/username/Desktop/File.txt.
- File naming conventions: Windows file names can include spaces, while Linux file names cannot. Windows file names can also be up to 255 characters long, while Linux file names are limited to 255 bytes.
- File permissions: Linux uses a more granular and flexible system for file permissions, which allows for more fine-grained control over who can access files and what they can do with them. Windows also has a permissions system, but it is less flexible and more difficult to configure.
- Case sensitivity: Linux file systems are case-sensitive, meaning that File.txt and file.txt are two different files. Windows file systems are not case-sensitive, so these would be treated as the same file.
- File system hierarchy: Linux follows a hierarchical file system structure, where all files and directories are organized under the root directory (/). Windows also has a hierarchical file system structure, but it is organized around drive letters (C:, D:, etc.) rather than a single root directory.
In summary, Windows and Linux file systems have some key differences in terms of structure, naming conventions, permissions, and other features. Understanding these differences is important for working with files and directories on each operating system.
(c) Write about Least Recently Used page replacement algorithm all its variants
with an example.
The Least Recently Used (LRU) page replacement algorithm is a popular page replacement algorithm used in operating systems. It works by keeping track of the pages that have been used most recently, and evicting the least recently used page when a new page needs to be loaded into memory. LRU is based on the assumption that the pages that have been used recently are more likely to be used again in the near future.
There are several variants of the LRU algorithm:
- Stack-based LRU: In this variant, the pages are organized into a stack in the order of their most recent use. When a page is accessed, it is moved to the top of the stack. When a new page needs to be loaded into memory and there is no free space, the page at the bottom of the stack (i.e., the least recently used page) is evicted.
- Counter-based LRU: In this variant, each page has a counter associated with it that is incremented every time the page is accessed. When a new page needs to be loaded into memory and there is no free space, the page with the lowest counter value (i.e., the least recently used page) is evicted.
- Clock-based LRU: In this variant, the pages are organized in a circular buffer. Each page has a reference bit associated with it that is set to 1 when the page is accessed. A clock hand is used to iterate over the circular buffer, and when a new page needs to be loaded into memory and there is no free space, the clock hand is moved around the buffer until it finds a page with a reference bit set to 0. This page is evicted and replaced with the new page.
Example: Let’s assume that we have a physical memory of size 4, and the following page reference sequence: 1 2 3 4 1 2 5 1 2 3 4 5
- Stack-based LRU: Initially, the stack is empty. The first four pages are loaded into memory: 1 2 3 4. When page 1 is accessed again, it is moved to the top of the stack. When page 2 is accessed, it is moved to the top of the stack, pushing page 1 down. When page 3 is accessed, it is moved to the top of the stack, pushing page 2 and 1 down. When page 4 is accessed, it is moved to the top of the stack, pushing page 3, 2, and 1 down. When page 5 is accessed, the page at the bottom of the stack (i.e., page 1) is evicted, and replaced with page 5. The final page frames in memory are: 2 3 4 5.
- Counter-based LRU: Initially, all counters are set to 0. The first four pages are loaded into memory: 1 2 3 4. When page 1 is accessed again, its counter is incremented to 1. When page 2 is accessed, its counter is incremented to 1, and page 1’s counter is incremented to 2. When page 3 is accessed, its counter is incremented to 1, and page 1’s and 2’s counters are incremented to 3 and 2, respectively. When page 4 is accessed, its counter is incremented to 1, and page 1’s, 2’s, and 3’s counters are incremented to 4, 3, and 2, respectively. When page 5 is accessed, the page with the lowest counter value (i.e., page 2) is evicted, and replaced with page 5.
- The second variant of the LRU algorithm is called the Second Chance algorithm or the Clock algorithm. It is an improvement over the basic LRU algorithm as it reduces the overhead of searching for the least recently used page.
- The Second Chance algorithm maintains a circular queue of page frames. Each page frame has an additional bit called the reference bit. When a page is brought into a page frame, its reference bit is set to 1. Whenever a page is referenced (read or write operation), its reference bit is set to 1 again. The idea behind the Second Chance algorithm is to give a second chance to a page with reference bit 1 before replacing it.
(a) Explain the kdomain protection mechanism.
Domain protection is a security mechanism used in modern operating systems to protect sensitive resources and data from unauthorized access by processes running in other domains. A domain is a collection of processes that have a common security policy, such as a set of privileges and access control rules. The domain protection mechanism ensures that processes in one domain cannot access resources or data in another domain unless explicitly allowed by the security policy.
The domain protection mechanism is implemented using various techniques, including process isolation, privilege separation, and access control. Process isolation involves running processes in separate address spaces, preventing them from accessing memory or resources belonging to other processes. Privilege separation involves running processes with minimum privileges necessary to perform their tasks, reducing the risk of privilege escalation attacks. Access control involves using access control lists (ACLs) and other mechanisms to restrict access to resources and data based on the identity and permissions of the requesting process.
In modern operating systems, the domain protection mechanism is used in various scenarios, including user-space application sandboxing, virtualization, and containerization. For example, user-space application sandboxing involves running untrusted applications in a restricted environment with limited privileges and access to resources, preventing them from accessing sensitive data or resources on the system. Virtualization involves running multiple operating systems or applications on a single physical machine, with each virtual machine running in its own isolated domain. Containerization involves running multiple applications in separate containers, with each container running in its own isolated domain and sharing the underlying kernel and resources of the host operating system.
In summary, domain protection is an important security mechanism used in modern operating systems to ensure that sensitive resources and data are protected from unauthorized access by processes running in other domains. The mechanism is implemented using various techniques, including process isolation, privilege separation, and access control, and is used in various scenarios, including user-space application sandboxing, virtualization, and containerization.
(b) Write a short note: Unix kernel.
The Unix kernel is the core component of the Unix operating system that provides the basic services required for the system to function. It is responsible for managing system resources such as memory, CPU, and input/output devices, and for providing a programming interface for application programs to access these resources.
The Unix kernel is designed to be modular and configurable, allowing system administrators and developers to customize the system to their specific needs. It is written in the C programming language and consists of several layers, including the hardware abstraction layer, the process management layer, the file system layer, the network layer, and the device driver layer.
One of the key features of the Unix kernel is its support for multitasking and multiprocessing, allowing multiple processes and threads to run concurrently on the system. This makes Unix a popular choice for server applications and scientific computing, where high performance and scalability are important.
In addition to its core services, the Unix kernel also provides a range of system utilities and commands that are accessible from the command line interface, such as the shell, the file system utilities, and the network utilities. These tools are designed to be simple and efficient, allowing users to perform complex tasks with a few simple commands.
Overall, the Unix kernel is a critical component of the Unix operating system, providing a solid foundation for system administrators and developers to build upon. Its modular and configurable design, support for multitasking and multiprocessing, and rich set of system utilities and commands make it a powerful and flexible platform for a wide range of applications.
(c) Describe in detail about variety of techniques used to improve the efficiency
and performance of secondary storage.
Secondary storage devices, such as hard disk drives and solid-state drives, are crucial components of modern computer systems. They provide large amounts of storage capacity at relatively low cost, but their performance can be a bottleneck in some applications. To address this challenge, a variety of techniques have been developed to improve the efficiency and performance of secondary storage. Some of the most important techniques are discussed below.
- Caching: Caching is the process of storing frequently accessed data in a fast, accessible location, such as a solid-state drive or a portion of main memory. By accessing data from the cache instead of the slower secondary storage, the overall performance of the system can be improved significantly.
- Prefetching: Prefetching is a technique used to anticipate future data accesses and proactively load data into the cache or main memory. By prefetching data before it is actually needed, the system can avoid delays associated with secondary storage accesses.
- Compression: Compression is the process of reducing the size of data by encoding it in a more compact format. Compressed data requires less space on disk and can be transferred more quickly, improving overall system performance.
- Tiered storage: Tiered storage is a technique that uses multiple levels of storage devices, such as hard disk drives and solid-state drives, to improve performance and reduce costs. Frequently accessed data is stored on fast, expensive storage devices, while less frequently accessed data is stored on slower, less expensive devices.
- Data deduplication: Data deduplication is the process of identifying and removing duplicate data within a storage system. By eliminating redundant data, storage capacity is freed up and access times can be improved.
- Striping: Striping is a technique used in RAID systems to distribute data across multiple disks. This improves performance by allowing multiple disk accesses to occur simultaneously.
- Disk scheduling: Disk scheduling is the process of determining the order in which disk accesses are processed. Various algorithms, such as First-Come, First-Served (FCFS) and Shortest Seek Time First (SSTF), can be used to optimize disk scheduling and improve overall system performance.
- Solid-state drives: Solid-state drives (SSDs) are a type of storage device that use flash memory to store data. Compared to traditional hard disk drives, SSDs offer much faster access times and improved performance.
Overall, the variety of techniques used to improve the efficiency and performance of secondary storage reflects the importance of this component in modern computer systems. By using a combination of caching, prefetching, compression, tiered storage, data deduplication, striping, disk scheduling, and solid-state drives, system designers can optimize performance and reduce costs.
Read More : OOP GTU Paper Solution Winter 2021
Read More : OS Winter 2022 GTU Paper Solution
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.