Here, We provide OS GTU Paper Solution Winter 2022. Read the Full OS GTU paper solution given below.
Operating System Old Paper Winter 2022 [Marks : 70] : Click Here
(a) Differentiate multiprocessing and multiprogramming operating system.
| Parameter | Multiprocessing | Multiprogramming |
|---|---|---|
| Definition | An operating system that supports the execution of multiple processes simultaneously on multiple CPUs or cores. | An operating system that supports the execution of multiple processes on a single CPU by time-sharing the CPU. |
| Resource Sharing | Resources such as CPU, memory, and I/O devices are shared among processes. | Resources such as CPU and memory are time-shared among processes. |
| Concurrency | True parallelism among processes, meaning multiple processes can run simultaneously. | Simulated parallelism through time-sharing, meaning each process is allocated a small time slice to execute before giving up the CPU to another process. |
| Context Switching | Context switching involves saving and restoring the state of each CPU core or processor. | Context switching involves saving and restoring the state of each process, including CPU registers, program counter, and memory allocation. |
| Scheduling | Scheduling involves assigning processes to available CPUs or cores based on various scheduling algorithms. | Scheduling involves assigning a small time slice to each process and switching to the next process when the time slice expires. |
| Examples | Windows NT, Linux, Unix, macOS. | DOS, early versions of Windows, Unix, macOS. |
(b) Write the functions of operating system.
Here are the functions of an operating system:
- Process Management
- Memory Management
- Device Management
- File Management
- Security
- Networking
- User Interface
- System Monitoring
- Resource Allocation
- System Initialization
(c) What is process? Explain process control block with all parameters.
A process is a program in execution, which includes the current values of program counter, register, and variables in memory.
The operating system manages the execution of these processes, and to do so, it uses a data structure known as a Process Control Block (PCB). The PCB contains various parameters that describe the current state of a process and its execution environment.
PCB includes
| Parameter | Description |
|---|---|
| Process ID (PID) | A unique identifier assigned to each process by the operating system. |
| Process State | The current state of the process, which could be “ready,” “running,” “blocked,” or “terminated.” |
| Program Counter (PC) | A register that stores the memory address of the next instruction to be executed. |
| CPU Registers | The current values of all CPU registers, including general-purpose registers, stack pointer, and status register. |
| Memory Management Information | Information about the process’s memory allocation, such as the starting address, size, and page table information. |
| I/O Status Information | Information about the process’s I/O operations, such as the status of open files, pending I/O requests, and device registers. |
| CPU Scheduling Information | Information about the process’s scheduling priority, execution history, and other scheduling-related parameters. |
| Accounting Information | Information about the resources used by the process, such as CPU time, memory usage, and I/O operations. |
| Interprocess Communication (IPC) Information | Information about the process’s communication channels with other processes, such as shared memory, message queues, and semaphores. |
The PCB is a critical data structure used by the operating system to manage and control the execution of processes. By maintaining this information, the operating system can ensure that each process is executed fairly, efficiently, and without interfering with other processes or system resources.
(a) Differentiate user level and kernel level thread.
| User-Level Threads | Kernel-Level Threads |
|---|---|
| Implemented entirely in user space, with no kernel involvement. | Managed and supported by the kernel, with kernel-level scheduling and synchronization. |
| Thread creation, management, and scheduling are done by the user-level thread library. | Thread creation, management, and scheduling are done by the kernel. |
| User-level threads are lightweight and have a small memory footprint, making them fast and efficient. | Kernel-level threads are heavier and have a larger memory footprint due to their association with the kernel, which can impact performance. |
| User-level threads cannot take advantage of multiple CPUs or cores, as they are not visible to the kernel’s scheduler. | Kernel-level threads can be scheduled across multiple CPUs or cores, providing true parallelism. |
| User-level threads are not able to directly access kernel resources and services, such as device drivers and system calls, without going through the kernel-level thread. | Kernel-level threads can directly access kernel resources and services, providing better performance for system calls and I/O operations. |
| Examples of user-level thread libraries include POSIX threads (pthreads), Windows fibers, and Green threads. | Examples of kernel-level thread implementations include the Linux Native POSIX Thread Library (NPTL) and the FreeBSD kernel thread subsystem. |
(b) What is scheduling? Explain the types of schedulers.
Scheduling is the process of selecting the next task or process to be executed by the CPU. The goal of scheduling is to optimize the use of CPU resources, ensuring that each task or process gets a fair share of CPU time while maximizing system throughput and minimizing response time.
There are three types of schedulers:
Long-Term Scheduler:
- Also known as job scheduler, it is responsible for selecting which processes should be admitted into the system for execution.
- Its main goal is to keep the system busy by selecting a mix of I/O-bound and CPU-bound processes. The long-term scheduler is typically implemented in the operating system kernel.
Short-Term Scheduler:
- Also known as CPU scheduler, it is responsible for selecting which process should be executed next and allocating CPU time to each process.
- Its main goal is to maximize system throughput, minimize response time, and ensure fairness among processes. The short-term scheduler is typically implemented in the operating system kernel.
Medium-Term Scheduler:
- This is an optional scheduler that can be used in some operating systems to manage memory usage. It is responsible for swapping processes in and out of memory, based on their memory requirements and usage patterns.
- The medium-term scheduler can help to prevent memory thrashing and improve system performance.
(c) List out various criteria for good process scheduling algorithms.
Illustrate non-preemptive priority scheduling algorithm.
Various criteria for good process scheduling algorithms are:
- CPU Utilization
- Throughput
- Turnaround Time
- Waiting Time
- Response Time
Non-preemptive Scheduling Algorithm
- Non-preemptive priority scheduling is a scheduling algorithm in which each process is assigned a priority value, and the process with the highest priority is scheduled first.
- In case of a tie, the FCFS (First-Come, First-Serve) algorithm is used to break the tie.
- The non-preemptive priority scheduling algorithm is simple and easy to implement, but it can result in low CPU utilization and may lead to starvation for low-priority processes.
Consider the following table, which shows the process ID, arrival time, burst time, and priority for five processes:
| Process ID | Arrival Time | Burst Time | Priority |
|---|---|---|---|
| P1 | 0 | 5 | 2 |
| P2 | 1 | 3 | 1 |
| P3 | 2 | 8 | 3 |
| P4 | 3 | 6 | 2 |
| P5 | 4 | 4 | 1 |
We can schedule these processes using non-preemptive priority scheduling as follows:
- At time t=0, P1 is the only process in the ready queue, so it is scheduled first.
- At time t=5, P2 arrives and is added to the ready queue with priority 1.
- At time t=8, P4 arrives and is added to the ready queue with priority 2.
- At time t=10, P5 arrives and is added to the ready queue with priority 1.
- At time t=13, P2 finishes execution, and P5 is scheduled next.
- At time t=17, P1 finishes execution, and P4 is scheduled next.
- At time t=23, P3 arrives and is added to the ready queue with priority 3.
- At time t=29, P4 finishes execution, and P3 is scheduled next.
- At time t=37, P3 finishes execution, and all processes are complete.
The Gantt chart for this schedule is as follows:
| Process | P1 | P5 | P4 | P2 | P3 |
|---|---|---|---|---|---|
| Time | 0 | 5 | 17 | 13 | 29 |
(c) Differentiate process and thread. Explain process state diagram.
Process:
- A process is an instance of a program that is running on a computer system. It is a self-contained execution environment with its own memory space and system resources.
- Each process has at least one thread of execution, but can have multiple threads as well.
- Inter-process communication (IPC) is required to communicate between different processes.
- Processes are heavyweight and require more system resources to create and manage.
Thread:
- A thread is a lightweight process that exists within a process and shares the same memory and system resources as the process.
- Multiple threads within a process can run concurrently and communicate with each other through shared memory.
- Threads are more efficient and faster to create and manage than processes.
- Threads are used for achieving parallelism and multitasking within a single process.
Process State Diagram:

The state diagram of a process is a visual representation of the different states a process can be in during its lifetime. The typical process state diagram includes the following states:
New: This state represents the initial state of a process that has been created but not yet admitted by the operating system.Ready:This state represents the state of a process that is waiting to be assigned to a processor for execution.Running:This state represents the state of a process that is currently being executed by a processor.Waiting:This state represents the state of a process that cannot continue its execution because it is waiting for an event to occur or for a resource to become available.Terminated:This state represents the state of a process that has finished executing.
(a) Define following terms:
(i)Critical section (ii) Mutual exclusion (iii) Bounded waiting
(i) Critical section: A critical section is a section of code in a program that accesses shared resources such as shared data structures, files, or hardware devices, and can only be executed by one process or thread at a time to prevent race conditions and synchronization problems.
(ii) Mutual exclusion: Mutual exclusion is a mechanism that ensures that only one process or thread at a time can access a shared resource, such as a critical section, to prevent conflicts and maintain consistency.
(iii) Bounded waiting: Bounded waiting is a property that ensures that a process or thread that is waiting to access a shared resource will eventually be granted access, without being blocked indefinitely due to starvation or other factors. A bounded waiting algorithm guarantees that a process will get a chance to enter its critical section after a certain number of other processes have entered theirs.
(b) Define deadlock. Describe deadlock prevention in detail.
Deadlock is a situation in a computer system where two or more processes are unable to continue executing because they are blocked and waiting for each other to release a resource that they are holding.
Deadlock prevention is a technique used to avoid deadlock situations in a computer system by preventing one or more of the four necessary conditions for deadlock to occur. These four conditions are:
Mutual exclusion:At least one resource is held in a non-sharable mode by a process, and cannot be used by other processes.Hold and wait:A process holding at least one resource is waiting to acquire additional resources held by other processes.No preemption:A resource cannot be forcibly taken away from a process holding it.Circular wait:A circular chain of two or more processes exists, where each process is waiting for a resource held by the next process in the chain.
There are several techniques used for deadlock prevention, including:
Mutual exclusion avoidance:This technique involves making certain resources shareable, so that multiple processes can access them simultaneously. This technique is used for resources that can be shared, such as read-only data.Hold and wait avoidance:This technique involves requiring a process to request all the resources it needs at once, before starting execution. This technique is used to ensure that a process does not hold any resource while waiting for another resource.No preemption avoidance:This technique involves allowing a process to release a resource if it is waiting for another resource that cannot be allocated at the moment.
(c) Illustrate Readers and Writers IPC problem with solution.
The Readers and Writers problem is a classic synchronization problem in computer science, where multiple threads or processes compete for access to a shared resource, which can be read or written to. In this problem, multiple readers can access the shared resource simultaneously, but only one writer can access it at a time.
The problem can be formulated as follows:
- Multiple readers can simultaneously access the shared resource for reading.
- Only one writer can access the shared resource at a time for writing.
- While a writer is accessing the shared resource, no reader can access it for reading.
To solve this problem,
- we can use a solution known as the
Reader-Writer lock. The lock has two states: read mode and write mode. - When the lock is in read mode, multiple readers can access the shared resource simultaneously, but no writers are allowed to access it.
- When the lock is in write mode, only one writer can access the shared resource, and no readers are allowed to access it.
Here is an example implementation of the Reader-Writer lock in pseudocode:
shared resource
readers_count = 0
mutex = 1
read_lock = 1
write_lock = 1
Reader:
wait(mutex)
readers_count += 1
if readers_count == 1:
wait(write_lock)
signal(mutex)
# read the shared resource
wait(mutex)
readers_count -= 1
if readers_count == 0:
signal(write_lock)
signal(mutex)
Writer:
wait(read_lock)
wait(write_lock)
# write to the shared resource
signal(write_lock)
signal(read_lock)
(a) Explain Resource allocation graph.
The Resource Allocation Graph is a graphical representation of resource allocation and resource wait-for relationships between processes in an operating system. It is used to detect and prevent deadlocks in the system.
In a resource allocation graph, processes are represented as circles or nodes, and resources are represented as rectangles or squares. Directed edges are used to represent the requests and allocations of resources between processes and resources.
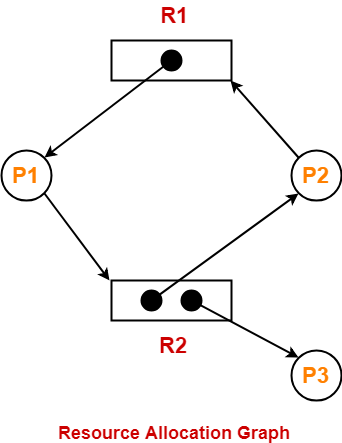
(b) What is deadlock? List the conditions that lead to deadlock.
Deadlock is a situation that occurs in a computer system when two or more processes are unable to proceed because each is waiting for a resource that is being held by another process in the same set of processes. This results in a standstill, where no progress can be made and the system becomes unresponsive.
The four necessary conditions for deadlock are:
Mutual exclusion:A resource can be held by only one process at a time.Hold and wait:A process holding at least one resource is waiting to acquire additional resources held by other processes.No preemption:A resource can only be released voluntarily by the process holding it, after the process has completed its task.Circular wait:A set of processes is waiting for each other to release the resources they hold, in a circular chain.
(c) Explain the Banker’s algorithm for deadlock avoidance with an
example.
(a) Explain segmentation.
- Segmentation is a memory management scheme used by operating systems to divide the main memory of a computer into segments or logical units. In this scheme, a program is divided into smaller segments that are loaded into separate memory locations. Each segment represents a different logical unit of the program, such as code, data, or stack.
- Segments are usually defined by the program itself or the operating system. Each segment is identified by a segment number or name and has a defined length. The segments can be of different sizes, and their lengths can be changed dynamically during program execution.
- Segmentation provides several benefits over other memory management schemes, such as paging. Some of these benefits are:
Protection: Segmentation provides protection against unauthorized access to memory by dividing the memory into logical units, and each segment can be protected individually.Sharing: Segments can be shared among different processes, allowing multiple processes to access the same segment simultaneously.Dynamic memory allocation:Segments can be allocated and deallocated dynamically, allowing for better utilization of memory.
(b) What is external fragmentation? Explain the solution to external
fragmentation.
External fragmentation is a problem that can occur in a memory management system where memory becomes fragmented into small, unused holes or free areas. This fragmentation happens when memory is allocated and deallocated in a non-contiguous way, leaving gaps of unused memory between allocated blocks.
Over time, these gaps can accumulate and become large enough to prevent new memory requests from being satisfied, even though there may be sufficient total free memory available.

Here in this figure, you can see the Fragments in the memory Fragment 1, Fragment 2 and Fragment 3.
The solution to external fragmentation is called compaction, which involves moving the allocated blocks of memory so that they are contiguous, and the free memory gaps are eliminated or reduced. This process can be costly in terms of time and system resources, and it may not always be possible or practical to implement.
Another solution to external fragmentation is to use virtual memory, which allows a process to use memory that is not currently in main memory. In virtual memory, the process is divided into pages, and each page is loaded into memory only when it is needed. The virtual memory manager is responsible for managing the allocation of pages and their placement in memory. This reduces the effects of external fragmentation because the operating system can use any available memory to satisfy memory requests.
(c) Explain paging hardware with TLB.
Paging is a memory management technique used by operating systems to allocate memory to processes in small, fixed-size chunks called pages. The hardware used for paging includes a memory management unit (MMU) and a translation lookaside buffer (TLB).
The MMU is responsible for translating the logical addresses used by processes into physical addresses used by the memory hardware. The MMU does this by using a page table, which is a data structure that maps logical page numbers to physical page numbers. The page table is stored in main memory, and each process has its own page table.
The TLB is a cache that stores recently accessed page table entries, making the address translation process faster. When a process requests access to a particular logical address, the MMU first looks for the corresponding page table entry in the TLB. If the entry is found in the TLB, the physical address is obtained directly. If the entry is not found in the TLB, the MMU looks up the page table in main memory, updates the TLB with the new entry, and retrieves the physical address.
The TLB contains a limited number of entries, and if all entries are occupied, a replacement algorithm is used to remove an existing entry and replace it with the new entry. The most commonly used replacement algorithm is the least recently used (LRU) algorithm, which removes the entry that has not been used for the longest time.

(a) Explain address binding.
Address binding is an important concept in operating systems as it enables the translation of logical addresses used by a process into physical memory addresses used by the hardware.
This translation is done by the operating system’s memory management unit (MMU), which is responsible for mapping logical addresses to physical addresses.
The process of address binding in an operating system involves several steps. First, the process is allocated a logical address space, which is divided into pages or segments. These logical addresses are typically generated by the compiler or linker and are symbolic references to functions, variables, and other program elements.
When the process starts running, the operating system’s MMU translates the logical addresses into physical addresses by looking up the page table or segment table for the process. The page table or segment table maps logical addresses to physical addresses, and it is maintained by the operating system.
(b) Explain following allocation algorithm 1) First Fit 2) Best Fit.
First Fit Algorithm:
The First Fit algorithm is a simple memory allocation technique that searches for the first available block of memory that is large enough to accommodate the requested memory size. This algorithm starts at the beginning of the free memory list and searches through the list until a suitable block of memory is found. The first block that is large enough to accommodate the requested size is allocated to the process, and the remaining portion of the block (if any) is returned to the free memory list.
Advantages of First Fit:
- Simple and easy to implement
- Memory allocation is fast as it does not require much searching.
Disadvantages of First Fit:
- Can lead to external fragmentation, which occurs when there are many small blocks of free memory scattered throughout the memory space that cannot be used for larger memory allocations.
Best Fit Algorithm:
The Best Fit algorithm is a more complex memory allocation technique that searches for the smallest block of free memory that is large enough to accommodate the requested memory size. This algorithm scans through the entire free memory list to find the block that is the closest in size to the requested memory size. The block that is allocated to the process is the one that is the smallest size and can still accommodate the requested memory size. Any remaining portion of the block is returned to the free memory list.
Advantages of Best Fit:
- Results in less external fragmentation than First Fit.
- More efficient memory utilization compared to First Fit.
Disadvantages of Best Fit:
- The search process can be time-consuming as the algorithm must scan through the entire free memory list to find the best fit.
- Can lead to internal fragmentation, which occurs when a process is allocated a memory block that is larger than its actual memory requirements, resulting in unused memory.
(c) What is page fault? Explain steps to handle page fault with diagram.
In virtual memory systems, a page fault occurs when a process attempts to access a page that is not currently in main memory (RAM). The operating system then needs to handle this page fault to bring the required page into memory before allowing the process to continue executing.
The steps to handle a page fault are as follows:
- The processor generates a virtual address, which is then translated by the memory management unit (MMU) into a physical address.
- If the page corresponding to the physical address is not present in main memory, a page fault occurs.
- The operating system then saves the current context of the process, which includes the program counter, processor registers, and other relevant information, to the process control block (PCB).
- The operating system determines the location of the required page and initiates a page fault handler to bring the required page into main memory.
- Once the page has been loaded into memory, the operating system updates the page table to indicate that the page is now present in main memory.
- The operating system then restores the context of the process and allows it to continue executing from the point of the page fault.

(a) Discuss the major goals of I/O software.
The major goals of I/O software are as follows:
- Device independence: I/O software should shield application programs from the details of specific I/O devices by providing a device-independent interface. This allows application programs to access I/O devices without having to know the details of the underlying hardware.
- Uniform naming: I/O software should provide a uniform naming scheme for all I/O devices, regardless of their type or location. This allows application programs to access I/O devices in a consistent manner, regardless of the physical location of the device.
- Error handling: I/O software should provide a robust mechanism for handling errors that may occur during I/O operations. This includes detecting and reporting errors, retrying failed operations, and providing a consistent error handling interface for application programs.
- Buffering: I/O software should provide a buffering mechanism to improve the efficiency of I/O operations. This includes buffering data in memory to reduce the number of physical I/O operations required, and providing a mechanism for asynchronous I/O operations to allow application programs to continue processing while I/O operations are in progress.
- Caching: I/O software should provide a caching mechanism to improve the performance of frequently accessed data. This includes caching data in memory to reduce the number of physical I/O operations required and providing a mechanism for managing cache consistency.
- Scheduling: I/O software should provide a scheduling mechanism to optimize the use of I/O devices and to avoid resource contention. This includes providing a mechanism for prioritizing I/O operations and for managing I/O queues.
(b) What is virtualization? Explain the benefits of virtualization.
Virtualization is the process of creating a virtual version of a computer system or resource, such as an operating system, a server, a storage device, or a network, using software rather than physical hardware.
The benefits of virtualization include:
- Server consolidation: Virtualization allows multiple virtual servers to be hosted on a single physical server, which can lead to significant cost savings by reducing the need for additional hardware.
- Improved resource utilization: Virtualization allows IT administrators to allocate computing resources, such as CPU, memory, and storage, more efficiently, resulting in better resource utilization and reduced waste.
- Enhanced scalability and flexibility: Virtualization allows IT administrators to quickly provision or de-provision virtual machines, which provides greater flexibility and scalability to accommodate changing business needs.
- Increased reliability and availability: Virtualization provides greater reliability and availability by allowing virtual machines to be easily migrated to another physical host in the event of hardware failure or maintenance.
- Simplified management and automation: Virtualization allows IT administrators to manage and automate complex IT environments more easily, reducing the need for manual intervention and improving overall system management.
(c) Draw the block diagram for DMA. Write steps for DMA data transfer.
(a) Differentiate block and character devices.
| Block Devices | Character Devices |
|---|---|
| Transfer data in fixed-size blocks or chunks | Transfer data one character at a time |
| Used for random access | Used for sequential access |
| Examples include hard drives, solid-state drives, and USB flash drives | Examples include keyboards, mice, and printers |
| Slower than character devices due to additional overhead | Faster than block devices due to simpler data transfer |
| Commonly used for storage | Commonly used for input and output |
(b) Explain following Unix command: grep, sort, chmod, mkdir.
grep: This command is used to search for a specific pattern or text in a file or set of files.
-
grep [options] pattern [file(s)]. - For example, to search for the word “hello” in a file called “example.txt”, you would use the command
grep hello example.txt. Some commonly used options withgrepinclude-ito ignore case,-nto show line numbers, and-rto recursively search subdirectories.
sort: This command is used to sort the lines of text in a file or set of files.
sort [options] [file(s)].- For example, to sort the lines of a file called “example.txt” in alphabetical order, you would use the command
sort example.txt. Some commonly used options withsortinclude-rto sort in reverse order,-nto sort numerically, and-uto remove duplicate lines.
chmod: This command is used to change the permissions of a file or directory in Unix or Linux. The syntax for using chmod is:
chmod [options] mode file(s).- The
modeparameter specifies the new permissions to be set, and can be expressed using a three-digit octal code or a symbolic representation. For example, to give the owner of a file read, write, and execute permissions, and only read permissions to everyone else, you would use the commandchmod 744 file.txt.
mkdir: This command is used to create a new directory in Unix or Linux.
- The syntax for using
mkdiris:mkdir [options] directory. - For example, to create a new directory called “mydir”, you would use the command
mkdir mydir. Some commonly used options withmkdirinclude-pto create parent directories if they don’t already exist, and-mto set the permissions of the new directory.
(c) Write short note on RAID levels.
RAID (Redundant Array of Independent Disks) is a technology that combines multiple physical hard drives into a single logical unit to improve performance, reliability, or both. There are several different levels of RAID, each with its own tradeoffs between performance, reliability, and cost. Some of the commonly used RAID levels are:
RAID 0 (striping):This level offers improved performance by dividing data across multiple disks, allowing data to be accessed more quickly. However, it does not provide any fault tolerance, and the failure of a single disk can result in data loss.RAID 1 (mirroring):This level provides improved reliability by maintaining an exact copy (or mirror) of data on two disks. If one disk fails, the other disk can continue to function without any data loss. However, it requires twice the amount of storage capacity compared to RAID 0.RAID 5 (striping with parity):This level offers both improved performance and fault tolerance. Data is striped across multiple disks, and parity information is stored on a separate disk. In the event of a single disk failure, the parity information can be used to rebuild the missing data. However, it requires at least three disks, and the performance can be affected during the rebuilding process.RAID 6 (striping with double parity):This level is similar to RAID 5, but with two sets of parity information. This provides improved fault tolerance, as it can tolerate the failure of two disks simultaneously. However, it requires at least four disks and has higher overhead compared to RAID 5.RAID 10 (striping with mirroring):This level combines the performance benefits of RAID 0 with the redundancy of RAID 1. Data is striped across multiple disks, and each stripe is mirrored to another set of disks. This provides high performance and fault tolerance, but requires a minimum of four disks and has high cost due to the storage overhead.
Read More : OOP GTU Paper Solution Winter 2021
Read More : DS GTU Paper Solution Winter 2021
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.