Here, We provide Software Engineering GTU Paper Solution Winter 2022. Read the Full SE GTU paper solution given below. Software Engineering GTU Old Paper Winter 2022 [Marks : 70] : Click Here
(a) Explain the process model which is used in situations where the user
requirements are not well understood.
The process model used in situations where user requirements are not well understood is commonly referred to as an iterative or incremental process model. This type of process model is well-suited for projects or situations where the requirements are unclear or constantly changing, and it allows for flexibility and adaptability throughout the development process. Here are the main characteristics of an iterative or incremental process model:
- Iterative Development: In this approach, the development process is broken down into multiple iterations or cycles, with each iteration producing a partial or incremental version of the final product. The iterations are designed to be short, typically lasting a few weeks, and they focus on developing a specific subset of functionality or addressing a particular aspect of the requirements.
- Feedback and Evaluation: At the end of each iteration, the developed product is evaluated, and feedback is gathered from users, stakeholders, or other relevant parties. This feedback is used to refine and improve the subsequent iterations, allowing for adjustments to be made based on the evolving understanding of user requirements.
- Incremental Delivery: With each iteration, a partial version of the product is delivered to the users or stakeholders, providing an opportunity for early feedback and validation of the product. This allows for continuous validation of requirements and helps to minimize the risk of developing a product that does not meet user needs.
- Flexible and Adaptive: The iterative or incremental process model allows for flexibility and adaptability, as requirements can change and evolve over time. The development team can incorporate new information or insights gained from user feedback into subsequent iterations, resulting in a product that better aligns with user needs.
- Collaboration and Communication: Communication and collaboration among team members, users, and stakeholders are critical in this process model. Frequent interaction and feedback loops ensure that requirements are clarified, and the development team and users are on the same page.
- Risk Management: The iterative or incremental process model provides opportunities for early identification and mitigation of risks. As each iteration is completed, risks can be evaluated, and appropriate measures can be taken to address them in subsequent iterations.
- Continuous Improvement: The iterative or incremental process model fosters a culture of continuous improvement, where the development team learns from each iteration and applies the knowledge gained to subsequent iterations. This allows for the refinement of requirements, design, and implementation throughout the development process.
(b) Draw the extreme programming process.
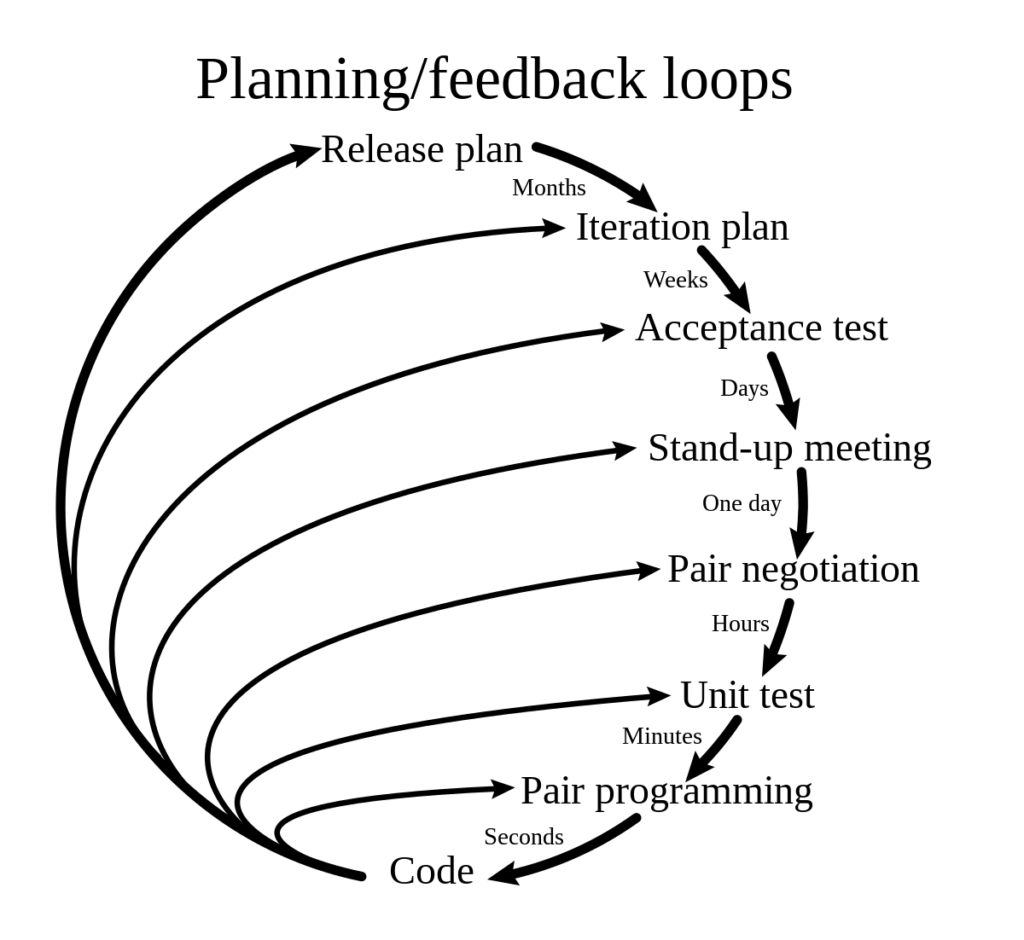
The Extreme Programming (XP) process typically consists of the following key practices:
- Continuous Integration: Developers integrate their code into a shared codebase multiple times per day to detect and fix issues early.
- Test-Driven Development (TDD): Developers write automated tests before writing the code, ensuring that the code meets the desired requirements and can be easily tested for quality.
- Small Releases: The software is released in small, frequent increments to gather feedback from users and stakeholders, and to allow for rapid iteration and improvement.
- On-site Customer: A customer representative is actively involved in the development process, providing feedback, clarifying requirements, and making decisions in real-time.
- Pair Programming: Developers work in pairs, with one writing code and the other reviewing it in real-time, fostering collaboration, knowledge sharing, and code quality.
- Continuous Refactoring: Code is continuously improved and optimized to maintain code quality and reduce technical debt.
- Simple Design: The focus is on keeping the design of the software simple, avoiding unnecessary complexity, and only adding features that are required.
- Sustainable Pace: Team members work at a sustainable pace, avoiding excessive overtime or burnout, to ensure productivity and quality.
- Collective Code Ownership: The entire team takes ownership of the codebase, and any team member can modify or improve the code as needed.
- Regular Meetings: The team holds regular meetings, such as daily stand-ups, sprint planning, and retrospective meetings, to ensure effective communication, coordination, and feedback.
(c) Explain Software Engineering as a Layered Technology.
Software engineering can be conceptualized as a layered technology, where each layer represents a different aspect of the software development process. This conceptualization helps in understanding the different stages, activities, and roles involved in software engineering. Here’s an explanation of software engineering as a layered technology:
- Process Layer: The process layer represents the high-level framework and methodology used in software development. It includes various process models such as waterfall, agile, DevOps, etc., that define how the development activities are organized, coordinated, and executed.
- Methods Layer: The methods layer represents the specific techniques and practices used to perform different tasks during software development. It includes activities such as requirements gathering, design, coding, testing, and deployment. Different methods and techniques are used at each stage to perform these tasks effectively.
- Tools Layer: The tools layer represents the software and hardware tools used to support the software development process. These tools include integrated development environments (IDEs), version control systems, bug tracking tools, automated testing tools, project management tools, etc., that assist software engineers in performing their tasks efficiently.
- Quality Assurance Layer: The quality assurance layer represents the activities and techniques used to ensure the quality of the software being developed. This includes activities such as software testing, code reviews, static analysis, dynamic analysis, and other quality assurance practices to detect and fix defects and ensure the software meets the desired quality standards.
- Management Layer: The management layer represents the activities related to project management, team coordination, and communication. It includes activities such as project planning, scheduling, resource allocation, risk management, and communication management, which are essential for successful software development.
- Human Layer: The human layer represents the people involved in the software development process, including software engineers, project managers, stakeholders, and end-users. Human factors such as skills, expertise, communication, collaboration, and decision-making play a crucial role in the success of software engineering.
(a) Define Generalization. Explain with example.
In the context of computer programming and software engineering, generalization refers to the process of creating a more abstract, generalized, or reusable form of code or functionality from specific instances or examples. It involves extracting common features or behaviors from specific instances and creating a more generalized solution that can be used in a broader context.
For example, let’s consider a scenario where you are developing a software application to model different types of vehicles, such as cars, motorcycles, and buses. You may start by creating separate classes or objects for each specific type of vehicle with their own unique properties and behaviors. However, you may notice that these different types of vehicles share certain common properties, such as a make, model, and year of manufacture, as well as common behaviors, such as starting, stopping, and accelerating.
In this case, you could use the process of generalization to create a more abstract or generalized class or object that captures the common properties and behaviors of all types of vehicles, and then derive specific classes or objects for each type of vehicle that inherit or specialize from the generalized class. This generalized class could have attributes like “make”, “model”, “year”, and methods like “start()”, “stop()”, “accelerate()”, which can be shared and reused across different types of vehicles.
(b) Define feasibility study. Enlist and explain the contents to be included
in the feasibility study report.
Feasibility study is an important phase in the software development process that aims to assess the viability, practicality, and profitability of a proposed software project or system. It involves conducting a thorough analysis of various aspects, such as technical, economic, legal, operational, and scheduling, to determine whether the project is feasible and worth pursuing.
A feasibility study report typically includes the following contents:
- Executive Summary: This section provides a brief overview of the feasibility study, including the purpose, scope, and key findings. It serves as a high-level summary for stakeholders who may not have time to read the entire report.
- Introduction: This section introduces the background and context of the proposed software project, including its objectives, scope, and stakeholders. It also outlines the purpose and scope of the feasibility study.
- Technical Feasibility: This section assesses the technical feasibility of the proposed software project. It includes an analysis of the technical requirements, existing technology infrastructure, technical risks, and challenges, as well as the availability of necessary technical resources and expertise.
- Economic Feasibility: This section evaluates the economic feasibility of the proposed software project. It includes a cost-benefit analysis that considers the estimated costs and potential benefits of the project. It may also include financial projections, return on investment (ROI), and other financial metrics to determine the economic viability of the project.
- Legal Feasibility: This section examines the legal feasibility of the proposed software project. It includes an analysis of legal and regulatory requirements, intellectual property considerations, licensing, and other legal aspects that may impact the project’s feasibility.
- Operational Feasibility: This section assesses the operational feasibility of the proposed software project. It includes an analysis of the operational requirements, including staffing, training, and other resources needed for the project’s successful implementation and operation.
- Scheduling Feasibility: This section evaluates the scheduling feasibility of the proposed software project. It includes an analysis of the proposed timeline, milestones, and critical path, as well as any potential scheduling constraints or risks that may impact the project’s feasibility.
- Conclusion: This section provides a summary of the key findings from the feasibility study, including the overall feasibility assessment and any recommendations for the next steps.
- Appendices: This section may include supporting documents, data, and references used in the feasibility study, such as detailed cost estimates, financial projections, technical documentation, legal documents, and other relevant information.
(c) Explain Project Scheduling Process. Also Explain Gantt Chart in detail
The project scheduling process is an important step in project management that involves creating a timeline or schedule for the various tasks and activities that need to be completed in a project. A well-designed project schedule helps in organizing and coordinating project activities, allocating resources effectively, tracking progress, and ensuring timely project completion.
The project scheduling process typically involves the following steps:
- Define project tasks: Identify and define the tasks or activities that need to be completed in the project. Tasks should be specific, measurable, and achievable, and they should have clear start and end dates.
- Determine task dependencies: Identify the dependencies or relationships between tasks, such as which tasks must be completed before others can start, and which tasks can be worked on simultaneously.
- Estimate task durations: Estimate the time required to complete each task. Task durations should be based on historical data, expert judgment, or other estimation techniques.
- Allocate resources: Determine the resources required for each task, such as personnel, equipment, and materials. Allocate resources based on availability, skills, and dependencies.
- Create a project schedule: Use project scheduling tools or software to create a visual representation of the project schedule. This can be in the form of a Gantt chart, which is a popular project scheduling technique.
A Gantt chart is a graphical representation of a project schedule that displays project tasks or activities on a horizontal timeline. It provides a visual overview of the project schedule, showing the start and end dates of each task, their duration, and their dependencies. Gantt charts can help project managers and team members understand the project timeline, track progress, and identify potential scheduling conflicts or delays.
In a Gantt chart, tasks are represented as horizontal bars along the timeline. The length of each bar represents the duration of the task, and the position of the bar on the timeline represents the start and end dates of the task. Task dependencies are shown using arrows or lines connecting the bars, indicating the relationships between tasks.
Gantt charts typically include the following elements:
- Task names: The names or descriptions of the tasks or activities to be completed in the project.
- Timeline: The horizontal timeline that represents the project duration, showing the start and end dates of the project.
- Task bars: The horizontal bars representing the tasks, with their length indicating the duration of the tasks.
- Dependencies: The arrows or lines connecting the task bars, showing the dependencies or relationships between tasks.
- Milestones: Significant events or milestones in the project, represented as vertical lines or diamonds on the timeline.
- Resources: The allocation of resources to tasks, such as personnel or equipment, indicated on the task bars.
(c) Describe CASE building block.
CASE (Computer-Aided Software Engineering) refers to a collection of software tools and techniques that assist software engineers in automating various tasks and activities involved in software development. CASE tools are used to support the entire software development life cycle (SDLC), from requirements gathering to maintenance and testing. CASE building blocks are the fundamental components or functionalities of CASE tools that collectively enable software engineers to streamline their work and improve productivity. The typical building blocks of CASE tools include:
- Diagramming Tools: These tools provide graphical representations of software components, relationships, and interactions. They may include tools for creating flowcharts, data flow diagrams, entity-relationship diagrams, state-transition diagrams, and other visual representations that help in understanding and documenting software requirements, design, and architecture.
- Documentation Tools: These tools facilitate the creation, management, and organization of software documentation. They may include tools for generating software documentation automatically, managing documentation templates, and maintaining version control of documentation.
- Analysis Tools: These tools help in analyzing software requirements and design, identifying potential issues or conflicts, and validating software models or specifications. They may include tools for requirements analysis, design analysis, code analysis, and other types of analysis to ensure compliance with software standards and best practices.
- Code Generation Tools: These tools automatically generate code based on software models or specifications. They may include tools for generating code in programming languages such as Java, C++, Python, or other languages, based on design models, templates, or predefined patterns.
- Testing Tools: These tools assist in designing, executing, and managing software testing activities. They may include tools for creating test cases, managing test data, executing tests, and analyzing test results. Testing tools help in automating the testing process and identifying defects or issues in the software.
- Project Management Tools: These tools provide functionalities for managing software development projects, including project planning, scheduling, resource allocation, and progress tracking. They may include tools for creating project plans, managing tasks and milestones, tracking progress, and generating reports on project status.
- Configuration Management Tools: These tools help in managing changes to software configurations, including version control, configuration control, and configuration auditing. They may include tools for managing source code, tracking changes, merging code changes, and managing software configurations across different environments.
- Collaboration Tools: These tools facilitate communication and collaboration among software development team members. They may include tools for sharing documents, managing discussions, coordinating tasks, and tracking team progress. Collaboration tools help in improving team communication, coordination, and productivity.
(a) Explain the different phases of Waterfall model.
The Waterfall model is a traditional software development model that follows a linear, sequential approach to software development. It consists of several distinct phases, each building upon the outputs of the previous phase. The different phases of the Waterfall model are as follows:
- Requirements Gathering: In this phase, software requirements are gathered from stakeholders, including end-users, customers, and other relevant parties. Requirements are documented in detail, including functional and non-functional requirements, and are approved by stakeholders before proceeding to the next phase.
- System Design: In this phase, the system’s overall design is created based on the gathered requirements. This includes defining the system architecture, identifying software components, creating data flow diagrams, creating user interface designs, and other system-level design activities.
- Implementation: In this phase, the software is developed based on the system design. The code is written, compiled, and tested, and the software components are integrated to create the final product. This phase involves programming, debugging, and unit testing of the software.
- Testing: In this phase, the software is thoroughly tested to identify defects or issues. This includes functional testing, performance testing, security testing, and other types of testing as per the requirements. Defects are reported, fixed, and retested until the software is deemed acceptable and ready for deployment.
- Deployment: In this phase, the software is deployed in the production environment and made available for end-users. This includes installation, configuration, and setup of the software in the target environment.
- Maintenance: After deployment, the software is monitored and maintained to address any issues that arise in the production environment. This includes bug fixes, performance optimizations, and other maintenance activities to ensure the software remains functional and meets the evolving needs of the users.
(b) Explain steps involved during the prototyping
Prototyping is a software development approach that involves creating an initial working model of the software to gather feedback, test functionality, and refine requirements. The steps involved in the prototyping process are as follows:
- Identify Requirements: In this step, the initial requirements for the software are identified, either through discussions with stakeholders or based on existing documentation. These requirements serve as the foundation for the prototype.
- Design Prototype: Once the requirements are identified, the next step is to design the prototype. This involves creating a high-level design of the software, including user interfaces, functionality, and other relevant aspects. The design should be focused on meeting the specific objectives and goals of the prototype.
- Develop Prototype: After the design is finalized, the prototype is developed. This typically involves creating a working model of the software that includes the basic functionality and features identified in the requirements. The development may involve rapid application development (RAD) techniques, such as using visual tools, low-code or no-code platforms, or other techniques to quickly build the prototype.
- Test Prototype: Once the prototype is developed, it is tested to validate its functionality and gather feedback. This may involve different types of testing, including functional testing, usability testing, and other relevant testing methods. Feedback from stakeholders, end-users, and other relevant parties is collected and analyzed.
- Refine Prototype: Based on the feedback received during testing, the prototype is refined. This may involve making changes to the design, functionality, or other aspects of the software to address any issues or concerns raised during testing. The goal is to improve the prototype and align it with the desired objectives and requirements.
- Repeat Testing and Refinement: After making changes to the prototype, it is tested again to ensure that the changes have been effective and the prototype is meeting the desired goals. This iterative process of testing and refinement continues until the prototype meets the desired objectives and requirements.
- Finalize Prototype: Once the prototype is refined and meets the desired objectives, it is finalized. This may involve documentation of the prototype, including user guides, technical documentation, and other relevant documentation. The final prototype may be used as a basis for further development or as a reference for the actual software development process.
(c) Explain Functional Requirement and Non-Functional Requirement
with example.
Functional requirements and non-functional requirements are two different types of requirements in software engineering that define the characteristics and behavior of a software system.
Functional Requirements: Functional requirements describe what the software system is supposed to do, and they focus on the functionality or features of the system. They specify the actions the system must be able to perform, the inputs it must accept, the outputs it must produce, and the overall behavior it must exhibit. Functional requirements are typically expressed in terms of inputs, processes, and outputs, and they are used to define the expected behavior of the software system.
Example of a functional requirement: Let’s consider a requirement for an online shopping system. A functional requirement could be: “The system shall allow users to add items to the shopping cart, view the contents of the shopping cart, and place an order for the items in the shopping cart.”
Non-Functional Requirements: Non-functional requirements, also known as quality attributes or characteristics, describe how well the software system is supposed to do what it does. They focus on the qualities or properties of the system, such as performance, reliability, security, usability, and maintainability. Non-functional requirements define the attributes that determine the overall quality and effectiveness of the software system.
Example of a non-functional requirement: Continuing with the example of the online shopping system, a non-functional requirement could be: “The system shall have a response time of less than 2 seconds for adding items to the shopping cart and placing an order, under normal load conditions.”
In summary, functional requirements define what the software system is supposed to do in terms of functionality or features, while non-functional requirements define how well the software system is supposed to do what it does in terms of quality attributes or characteristics. Both types of requirements are important for developing software systems that meet the needs and expectations of stakeholders and end-users.
OR
(a) Distinguish between verification and validation
Verification: Verification is the process of evaluating the software system or component during or after the development phase to determine if it meets the specified requirements. It involves checking whether the software is designed and implemented correctly, and whether it adheres to the specified design standards, guidelines, and conventions. Verification focuses on the internal consistency and correctness of the software system, without considering its actual functionality.
Examples of verification activities:
- Reviewing and inspecting software design documents to ensure they meet the specified requirements.
- Reviewing and analyzing the source code to ensure it follows coding standards and conventions.
- Performing static analysis of the software to identify potential issues, such as syntax errors or logical inconsistencies.
- Conducting walkthroughs and inspections to identify and fix defects in the software.
Validation: Validation is the process of evaluating the software system or component during or after the development phase to determine if it satisfies the specified requirements for its intended use. It involves checking whether the software performs as expected in its intended environment and whether it meets the needs and expectations of the end-users. Validation focuses on the external behavior and functionality of the software system.
Examples of validation activities:
- Conducting functional testing to verify that the software system meets the specified functional requirements.
- Performing performance testing to validate that the software system meets the specified performance requirements.
- Conducting usability testing to validate that the software system is easy to use and meets the needs of its intended users.
- Conducting security testing to validate that the software system meets the specified security requirements.
(b) Differentiate Software Engineering and Reverse Engineering.
Software Engineering: Software engineering is the systematic approach to designing, developing, testing, and maintaining software systems using established principles, methods, and tools. It involves the application of engineering principles and practices to the entire software development lifecycle, including requirements analysis, design, coding, testing, and maintenance. The goal of software engineering is to create high-quality, reliable, and maintainable software systems that meet the needs and expectations of stakeholders and end-users.
Reverse Engineering: Reverse engineering, on the other hand, is the process of analyzing and understanding the design, functionality, and behavior of an existing software system or component by examining its structure, code, and other artifacts. Reverse engineering is typically performed on legacy systems, proprietary software, or third-party software for which the original design documentation or source code may not be available. The purpose of reverse engineering is to gain insights into how a software system works, how it was designed, and how it can be modified or extended.
Main differences between Software Engineering and Reverse Engineering:
- Direction: Software engineering is a forward engineering process that involves designing, developing, and testing software systems from scratch, while reverse engineering is a backward engineering process that involves analyzing and understanding existing software systems.
- Focus: Software engineering focuses on creating new software systems that meet specific requirements, while reverse engineering focuses on understanding and analyzing existing software systems to gain insights or make modifications.
- Process: Software engineering follows a systematic approach involving requirements analysis, design, coding, testing, and maintenance, while reverse engineering involves analyzing and understanding the existing software system by examining its structure, code, and artifacts.
- Goal: The goal of software engineering is to create high-quality, reliable, and maintainable software systems, while the goal of reverse engineering is to gain insights into an existing software system or modify it for specific purposes.
- Availability of documentation: Software engineering typically involves designing and developing software systems based on documented requirements and design specifications, while reverse engineering may be necessary when documentation or source code is not available or inadequate.
- Legal and ethical considerations: Reverse engineering may have legal and ethical implications, as it may involve analyzing proprietary or copyrighted software without proper authorization. On the other hand, software engineering is performed in compliance with legal and ethical standards.
(c) Write a short note on formal technical review.
Formal Technical Review (FTR) is a well-defined and structured process used in software engineering to review and evaluate software artifacts such as design documents, source code, and other software-related materials. FTR is a collaborative effort involving a team of reviewers who follow a predefined process to carefully examine the software artifacts for defects, compliance with specifications, adherence to coding standards, and overall quality.
Here are some key points about Formal Technical Review (FTR):
- Process: FTR follows a systematic process that includes planning, preparation, review meeting, and follow-up. The process typically involves steps such as document distribution, review preparation, individual review, review meeting, and defect resolution.
- Participants: FTR involves a team of reviewers who have expertise in the relevant domain or technology. The team may include software developers, testers, architects, domain experts, and other stakeholders depending on the nature of the artifact being reviewed.
- Goals: The main goals of FTR are to identify defects, verify compliance with specifications, ensure adherence to coding standards and guidelines, and improve the overall quality of the software artifact being reviewed.
- Documentation: FTR often involves the use of checklists, templates, and other documentation to guide the review process. Reviewers may use checklists to systematically evaluate the artifact against predefined criteria and guidelines.
- Review Meeting: FTR typically includes a review meeting where the team discusses the findings, identifies and prioritizes defects, and comes up with recommendations for improvement. The review meeting is an opportunity for team members to discuss and clarify any issues or concerns related to the artifact being reviewed.
- Defect Resolution: FTR includes the process of resolving identified defects. The review team works with the artifact owner or author to address the identified defects, which may involve making corrections, clarifications, or updates to the artifact.
- Follow-up: FTR may include follow-up activities to ensure that the identified defects are resolved and the recommended improvements are implemented. Follow-up activities may include re-inspection, re-review, or verification of the implemented changes.
Benefits of FTR:
- Early detection and correction of defects, leading to improved software quality.
- Verification of compliance with specifications and coding standards.
- Knowledge sharing and learning among team members.
- Improved communication and collaboration among team members.
- Enhanced software development process and productivity.
(a) Explain 4 P’s of effective Project Management in detail.
The 4 P’s of effective project management refer to the four key elements that are essential for successful project management. They are:
- People: People are the most valuable resource in any project. Effective project management requires a skilled and motivated team that is capable of working collaboratively to achieve project goals. It involves assembling the right team members, defining roles and responsibilities, and ensuring that the team has the necessary skills, knowledge, and resources to complete the project successfully. Good communication, team collaboration, and leadership are critical for managing the people aspect of a project.
- Process: Process refers to the set of established procedures, methods, and techniques that are used to manage a project from initiation to closure. An effective project management process provides a structured framework for planning, executing, controlling, and closing projects. It includes activities such as defining project objectives, developing a project plan, assigning tasks, tracking progress, managing risks, and ensuring quality. A well-defined and documented project management process helps ensure that the project is executed in a systematic and organized manner, leading to higher chances of success.
- Product: Product refers to the deliverables or outcomes of the project. It includes the end result or the desired outcome that the project aims to achieve. An effective project management approach involves clearly defining the product requirements, setting realistic expectations, and managing changes to the product scope throughout the project lifecycle. It also involves monitoring and controlling the quality of the product to ensure that it meets the defined requirements and satisfies customer expectations.
- Project: Project environment refers to the external factors and constraints that can impact the success of a project. This includes factors such as organizational culture, project stakeholders, regulatory requirements, market conditions, and technological constraints. An effective project manager must be aware of the project environment and adapt the project management approach accordingly. This may involve building relationships with stakeholders, managing risks, addressing regulatory compliance, and keeping up with technological advancements that may affect the project.
(b) What is the importance of User Interface? Explain User Interface
design rules
The user interface (UI) of a software application or system is the visual and interactive medium through which users interact with the software. It serves as the point of communication and interaction between the user and the software, allowing users to input commands, receive feedback, and interpret the results. The importance of user interface design lies in its impact on the overall user experience (UX) of the software. A well-designed user interface can greatly enhance user satisfaction, usability, and productivity, while a poorly designed one can lead to frustration, confusion, and decreased user adoption.
Here are some key reasons why user interface design is important:
- Usability: A well-designed user interface should be easy to use, intuitive, and efficient. It should enable users to complete tasks quickly and accurately, with minimal errors. A usable UI allows users to interact with the software in a natural and intuitive way, without having to struggle to understand how to use it. This leads to increased user satisfaction and productivity.
- User Satisfaction: User satisfaction is a crucial factor in the success of any software application. A well-designed user interface that is visually appealing, responsive, and provides a positive user experience can greatly impact user satisfaction. Satisfied users are more likely to continue using the software, recommend it to others, and provide positive feedback, which can help improve the reputation and adoption of the software.
- Efficiency and Productivity: A well-designed user interface should enable users to complete tasks efficiently and accurately, minimizing the number of steps and clicks required to accomplish a task. This can greatly impact the productivity of users, as they can perform their tasks more quickly and with fewer errors. Efficient user interface design can save users time and effort, leading to increased productivity.
- Error Reduction: A well-designed user interface should help users avoid errors or provide meaningful feedback when errors occur. Clear and descriptive error messages, intuitive error handling, and helpful prompts can reduce the likelihood of user errors and help users recover from errors easily. This can prevent frustration and confusion, and result in a more positive user experience.
User interface design follows certain principles or rules that are commonly referred to as “User Interface Design Rules” or “UI Design Principles”. These rules provide guidelines for designing effective user interfaces. Some common UI design rules include:
- Clarity and simplicity: The user interface should be clear, simple, and easy to understand, with minimal complexity and clutter. Users should be able to quickly understand how to use the software and navigate through the interface without confusion.
- Consistency: The user interface should be consistent in its layout, design, and behavior. Consistency helps users develop a mental model of how the software works, making it easier for them to learn and use.
- Feedback and response: The user interface should provide feedback and response to user actions in a timely and meaningful manner. Feedback can be in the form of visual cues, sounds, or messages, helping users understand the outcome of their actions and guiding them through the interaction process.
- Flexibility and adaptability: The user interface should be designed to accommodate different users, devices, and contexts. It should be flexible and adaptable to different screen sizes, input methods, and accessibility needs, ensuring that all users can access and use the software effectively.
- Efficiency: The user interface should be designed to enable users to complete tasks quickly and with minimal effort. It should minimize the number of steps, clicks, and inputs required to accomplish a task, and should provide shortcuts or quick access to commonly used features or functions.
- Visual aesthetics: The visual design of the user interface should be visually appealing, professional, and consistent with the overall branding and style of the software or organization. A well-designed visual interface can create a positive impression and enhance the overall user experience.
(c) Explain Black box testing and White box testing. Discuss all the testing
strategies that are available.
Black Box Testing and White Box Testing are two different approaches to software testing, each with its own characteristics and techniques.
- Black Box Testing: Black Box Testing is a type of software testing where the internal structure or implementation of the software is not known to the tester. The tester focuses on testing the functionality of the software without any knowledge of the internal code or logic. It is called “black box” because the tester cannot see what is inside the “box” (i.e., the software), and only examines the inputs and outputs.
- White Box Testing: White Box Testing, also known as Structural Testing or Clear Box Testing, is a type of software testing where the tester has knowledge of the internal structure, implementation, and logic of the software. The tester examines the internal code, structure, and design to ensure that the software functions correctly as per the intended design.
Some common testing strategies or techniques available for software testing include:
- Unit Testing: Unit Testing is the testing of individual units or components of the software, such as functions, classes, or modules, to ensure that they function correctly as per the intended design.
- Integration Testing: Integration Testing is the testing of the interaction and integration between different units or components of the software to ensure that they work together correctly as a whole.
- System Testing: System Testing is the testing of the entire software system as a whole, including all its components and their interactions, to ensure that the software meets its intended requirements and functions correctly in its intended environment.
- Acceptance Testing: Acceptance Testing is the testing conducted by end-users or stakeholders to determine whether the software meets the specified requirements and is acceptable for use.
- Regression Testing: Regression Testing is the testing performed after making changes or modifications to the software to ensure that the existing functionality still works correctly and that the changes did not introduce any new defects or issues.
- Performance Testing: Performance Testing is the testing conducted to evaluate the performance and scalability of the software, including its response time, throughput, resource utilization, and stability under different loads or stress levels.
- Security Testing: Security Testing is the testing conducted to identify and address potential security vulnerabilities or weaknesses in the software, such as authentication, authorization, encryption, and data integrity.
- Usability Testing: Usability Testing is the testing conducted to evaluate the software’s usability and user-friendliness, including its ease of use, learnability, and user satisfaction.
- Exploratory Testing: Exploratory Testing is a dynamic testing approach where the tester actively explores the software while testing, without relying on predefined test cases, to discover defects that may not be identified through scripted testing.
- Ad-hoc Testing: Ad-hoc Testing is a type of informal testing where the tester randomly and spontaneously tests the software without any predefined plan or strategy, focusing on identifying defects through unplanned and unsystematic testing.
OR
(a) Explain Version and Change Control Management.
Version Control and Change Control Management are two important aspects of software configuration management, which help in managing changes and maintaining the integrity of software throughout its lifecycle.
- Version Control: Version Control, also known as Source Control or Revision Control, is the process of managing changes to software source code or other files, enabling multiple developers to work on the same codebase simultaneously without conflicts. It provides a systematic way to track and manage changes made to software files, allowing developers to collaborate, revert to previous versions, and maintain a complete history of changes.
Version Control typically involves the use of a version control system (VCS) that provides features such as version tracking, branching, merging, and conflict resolution. There are two main types of version control:
- Centralized Version Control: In centralized version control, there is a single repository that stores the master copy of the code, and developers check out and check in changes to this central repository. Examples of centralized version control systems include Apache Subversion (SVN) and Microsoft Team Foundation Server (TFS).
- Distributed Version Control: In distributed version control, each developer has a local copy of the entire repository, including the complete history of changes. Developers can commit changes to their local repository and then push those changes to a shared repository to synchronize with other developers. Examples of distributed version control systems include Git, Mercurial, and Bazaar.
- Change Control Management: Change Control Management, also known as Change Management, is the process of managing changes to software or system configurations in a controlled and systematic manner to minimize risks, ensure quality, and maintain stability. It involves the identification, evaluation, prioritization, approval, implementation, and verification of changes to software or systems, while maintaining proper documentation and communication.
Change Control Management typically follows a predefined set of steps or a formal process, including:
- Change Request: A change request is initiated by identifying a need for a change in the software or system configuration. It includes details such as the nature of the change, reasons for the change, impact analysis, and proposed solutions.
- Evaluation and Prioritization: Change requests are evaluated based on their impact, risks, benefits, and alignment with business objectives. They are prioritized according to their urgency and importance.
- Approval: Change requests are reviewed and approved by relevant stakeholders, such as project managers, product owners, or change control boards, based on established criteria and policies.
- Implementation: Approved changes are implemented by following proper procedures and guidelines, including development, testing, and deployment activities.
- Verification and Testing: Implemented changes are verified and tested to ensure that they have been properly implemented and have not introduced any unintended consequences or defects.
- Documentation and Communication: All changes, including their details, results, and documentation, are properly recorded and communicated to relevant stakeholders for reference and future audits.
(b) Explain Agile model
The Agile model is a software development approach that emphasizes flexibility, collaboration, and iterative development. It is based on the Agile Manifesto, which values individuals and interactions, working solutions, customer collaboration, and responding to change over processes and tools.
The Agile model is characterized by the following key principles:
- Iterative and incremental development: Instead of following a linear, sequential approach like the Waterfall model, Agile development is iterative and incremental. It involves breaking down the development process into smaller iterations, called sprints or iterations, where a working product increment is delivered at the end of each iteration.
- Cross-functional teams: Agile teams are typically cross-functional, consisting of members with diverse skills such as development, testing, design, and business analysis. These teams work collaboratively, communicate frequently, and make decisions collectively to deliver high-quality software.
- Customer collaboration: Agile development emphasizes close collaboration with customers and stakeholders throughout the development process. Customers are involved in providing feedback, clarifying requirements, and validating the software incrementally, ensuring that the end product meets their needs and expectations.
- Adaptive and flexible: Agile development embraces change and is responsive to changing requirements, priorities, and business needs. Agile teams are flexible and adaptive, capable of quickly adjusting their plans and processes based on feedback and changing circumstances.
- Continuous improvement: Agile development promotes continuous improvement through regular retrospectives, where the team reflects on their performance, identifies areas for improvement, and makes adjustments to their processes, tools, and practices.
Some of the popular Agile methodologies include Scrum, Kanban, Lean, Extreme Programming (XP), and Dynamic Systems Development Method (DSDM), among others. These methodologies provide specific frameworks, practices, and techniques for implementing Agile principles in software development.
(c) List and explain different types of testing done during testing phase.
During the testing phase of software development, various types of testing are conducted to ensure the quality and reliability of the software. Some of the commonly used types of testing are:
- Unit Testing: This type of testing focuses on testing individual units or components of the software, typically at the code level, to verify if they function as intended. It is usually performed by the developers themselves to catch defects early in the development process.
- Integration Testing: Integration testing verifies the proper integration and interaction between different components or modules of the software. It is conducted to detect any defects or issues arising from the interaction between different components of the software.
- System Testing: System testing is conducted to evaluate the entire software system as a whole, ensuring that all components are integrated correctly and the system functions as expected. It involves testing the system against the specified requirements and verifying its compliance with the intended behavior.
- Acceptance Testing: Acceptance testing is conducted to validate whether the software meets the acceptance criteria and requirements set by the stakeholders, including the end users. It is usually performed by the users or customer representatives to determine if the software is ready for production deployment.
- Performance Testing: Performance testing is conducted to evaluate the performance and scalability of the software under expected or peak load conditions. It involves measuring various performance parameters, such as response time, throughput, and resource utilization, to ensure that the software performs efficiently and meets the desired performance targets.
- Security Testing: Security testing is conducted to identify and address potential security vulnerabilities in the software. It involves testing the software for potential security breaches, unauthorized access, data leaks, and other security risks to ensure that the software is secure and protects sensitive data.
- Usability Testing: Usability testing is conducted to evaluate the user-friendliness, ease of use, and overall user experience of the software. It involves testing the software from the end users’ perspective to ensure that it meets their needs, is intuitive to use, and provides a positive user experience.
- Regression Testing: Regression testing is conducted to ensure that changes or fixes made to the software do not adversely impact existing functionality. It involves retesting previously tested functionalities to detect any regression defects that may have been introduced due to changes in the software.
- Smoke Testing: Smoke testing is conducted as an initial quick check of the software to verify if it is stable and ready for more comprehensive testing. It involves testing the basic functionalities or critical paths of the software to identify any major issues or showstopper defects early in the testing process.
- Exploratory Testing: Exploratory testing is a type of testing where testers actively explore the software to identify defects that may not be covered by scripted test cases. It involves ad-hoc testing, where testers use their domain knowledge, experience, and intuition to uncover defects.
(a) Draw E-R Diagram for Online shopping System
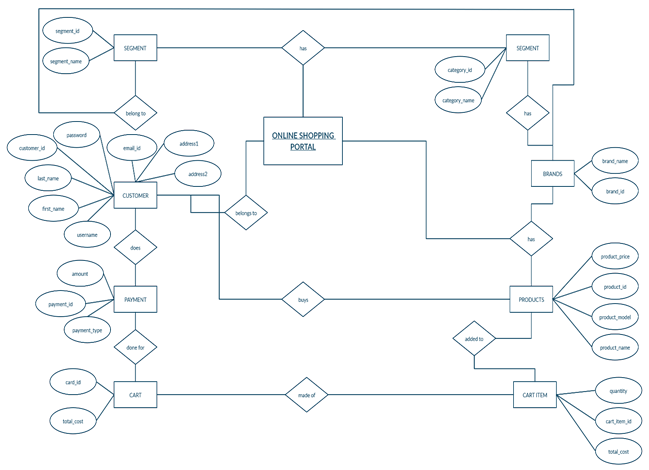
Entities:
- Customer: Represents the customers who use the online shopping system. It may have attributes like customer ID, name, email, contact number, address, etc.
- Product: Represents the products available for purchase in the online shopping system. It may have attributes like product ID, name, description, price, quantity, etc.
- Order: Represents the orders placed by customers. It may have attributes like order ID, date/time of order, total cost, etc.
Relationships:
- Customer-Product: Represents the relationship between customers and the products they have purchased. It may have attributes like purchase date, quantity, etc. This is a many-to-many relationship as a customer can purchase multiple products, and a product can be purchased by multiple customers.
- Customer-Order: Represents the relationship between customers and their orders. This is a one-to-many relationship as a customer can place multiple orders, but an order can only be associated with one customer.
- Product-Order: Represents the relationship between products and orders. This is a many-to-many relationship as an order can have multiple products, and a product can be associated with multiple orders. It may have attributes like quantity, price at the time of purchase, etc.
(b) What is architectural design? Enlist different style and patterns of
architecture.
Architectural design in software engineering is the process of defining the overall structure, organization, and relationship among the components of a software system. It involves making high-level design decisions that determine how the system will be structured and how its components will interact with each other.
There are various styles and patterns of architecture that can be used in software development, including:
- Layered Architecture: Also known as the n-tier architecture, this style involves dividing the system into distinct layers, each responsible for a specific set of functions. Typically, these layers include presentation, business logic, and data storage, with clear separation of concerns.
- Client-Server Architecture: This style involves dividing the system into two main components: the client, which is responsible for the user interface and user interactions, and the server, which handles the processing and storage of data.
- Microservices Architecture: This is an architectural style that involves breaking down a system into small, loosely coupled and independently deployable services that can be developed, deployed, and scaled independently. Each microservice is responsible for a specific business function and communicates with other microservices through lightweight protocols.
- Service-Oriented Architecture (SOA): This style involves designing software components as loosely coupled services that can be reused and combined to create complex applications. Services in SOA communicate with each other using standard protocols, such as SOAP or REST, and can be distributed across different platforms and technologies.
- Model-View-Controller (MVC) Pattern: This is a design pattern that separates the application logic into three main components: the model, which represents the data and business logic; the view, which displays the data to the user; and the controller, which handles user input and updates the model and view accordingly.
- Repository Pattern: This is a design pattern that involves separating the data access logic from the business logic by encapsulating data access operations in a separate repository component. This promotes separation of concerns and makes it easier to switch between different data storage technologies.
- Event-Driven Architecture (EDA): This is an architectural style that emphasizes the use of events to trigger and communicate changes in the system. Components in an EDA system communicate through events, and event handlers process these events and trigger appropriate actions or responses.
- Domain-Driven Design (DDD): This is an architectural style that emphasizes the close alignment of software design with the domain or problem space of the application. It involves identifying and modeling domain concepts, using domain-specific language, and organizing the software components around the domain concepts.
(c) Explain concept of Test Case
A test case is a specific scenario or set of conditions that is used to determine whether a software application or system is working correctly or not. It is a detailed description of a particular test that needs to be executed to verify the behavior of a software system or application under specific conditions. Test cases are an integral part of software testing and are used to ensure that the software meets the desired quality standards.
A typical test case consists of the following components:
- Test Case ID: A unique identifier that helps in tracking and managing the test cases.
- Test Case Description: A detailed description of the test scenario or condition being tested, including the expected behavior or outcome.
- Test Preconditions: Any specific conditions or setup that must be met before executing the test case, such as pre-existing data, configuration settings, or system state.
- Test Steps: A step-by-step sequence of actions that need to be performed to execute the test case, including input data, user interactions, and system operations.
- Expected Results: The expected outcome or behavior of the software system or application when the test case is executed.
- Actual Results: The actual outcome or behavior observed when the test case is executed, which is recorded during the test execution.
- Pass/Fail Criteria: The criteria used to determine whether the test case has passed or failed based on the actual results compared to the expected results.
- Test Status: The current status of the test case, such as “Pass,” “Fail,” “Blocked,” or “Not Run,” which helps in tracking the progress of testing.
OR
(a) What is Cyclomatic Complexity?
Cyclomatic complexity is a quantitative measure of the complexity of a software program’s control flow. It is a software metric that helps in assessing the complexity of a program based on the number of independent paths that can be executed in a program. It was developed by Thomas J. McCabe in 1976 and is widely used in software engineering to measure the complexity of software systems, particularly in the context of testing and quality assurance.
Cyclomatic complexity is calculated based on the number of decision points, such as conditional statements (if, switch), loop statements (for, while), and other control flow statements, in a software program. It represents the minimum number of linearly independent paths through the program, which means the minimum number of unique paths that need to be tested to achieve full coverage of the program’s control flow.
The formula to calculate cyclomatic complexity is:
V(G) = E – N + 2
where:
- V(G) is the cyclomatic complexity
- E is the number of edges (i.e., control flow branches) in the program
- N is the number of nodes (i.e., decision points) in the program
Cyclomatic complexity provides a quantitative measure of how complex a software program’s control flow is. Higher cyclomatic complexity values indicate more complex programs with more decision points and control flow branches, which may require more thorough testing to achieve adequate test coverage. Lower cyclomatic complexity values indicate simpler programs with fewer decision points and control flow branches, which may require less testing effort.
(b) Briefly Explain: Requirement Elicitation
Requirement elicitation, also known as requirement gathering or requirement discovery, is the process of identifying, gathering, and documenting requirements for a software system or application. It is an important step in the software development life cycle (SDLC) that involves understanding and capturing the needs, expectations, and constraints of stakeholders to define what the software system is supposed to do.
Requirement elicitation is a critical phase of software engineering as it lays the foundation for the development of a successful software system that meets the needs of its intended users. The goal of requirement elicitation is to ensure that all relevant and necessary requirements are identified and documented accurately and completely, so that they can serve as a basis for designing, implementing, and testing the software system.
The process of requirement elicitation typically involves the following steps:
- Identifying stakeholders: Stakeholders are individuals or groups who have an interest in the software system, such as users, customers, domain experts, business analysts, and other relevant parties. Identifying all relevant stakeholders is the first step in requirement elicitation.
- Conducting interviews: Interviewing stakeholders is a common method of requirement elicitation. This involves direct interaction with stakeholders to understand their needs, expectations, and constraints related to the software system. Interviews can be structured or unstructured, and can be conducted in person, over the phone, or through other communication channels.
- Facilitating workshops: Workshops or group meetings can be conducted with stakeholders to gather requirements collaboratively. This allows for brainstorming, discussions, and interactions among stakeholders to elicit requirements in a more dynamic and participatory manner.
- Reviewing existing documentation: Reviewing existing documentation such as business documents, user manuals, process flows, and other relevant materials can provide valuable insights into the requirements of the software system.
- Observing users: Observing users while they interact with existing systems or perform tasks related to the software system can provide firsthand information on their needs, preferences, and pain points, which can inform the requirements gathering process.
- Using questionnaires and surveys: Questionnaires and surveys can be used to gather requirements from a large number of stakeholders, or to collect feedback on specific aspects of the software system.
- Documenting requirements: Once the requirements are elicited, they need to be documented in a clear, concise, and unambiguous manner. This typically involves creating requirement documents, use cases, user stories, or other artifacts that capture the requirements in a format that can be easily understood by stakeholders and used as a reference throughout the software development process.
(c) Explain Risk Management. Explain RMMM plan
Risk management is an important process in software engineering that involves identifying, assessing, prioritizing, and mitigating risks associated with a software project. Risks can arise from various sources, such as technical, operational, organizational, or external factors, and can potentially impact the success of the software project. Risk management aims to proactively identify and address risks in order to minimize their negative impact on the project and increase the chances of project success.
One common approach to risk management is to create a Risk, Mitigation, Monitoring, and Management (RMMM) plan. The RMMM plan is a documented strategy that outlines the steps to be taken to identify, assess, prioritize, and mitigate risks throughout the software development process. The RMMM plan typically includes the following components:
- Risk Identification: This involves identifying potential risks that could arise during the software project. Risks can be identified through various techniques such as brainstorming sessions, historical data analysis, checklists, and expert judgment.
- Risk Assessment: Once risks are identified, they need to be assessed to determine their severity and likelihood of occurrence. This can be done using qualitative or quantitative techniques, such as probability and impact assessment, risk matrix, or risk scoring methods.
- Risk Prioritization: Risks are prioritized based on their severity and likelihood of occurrence to determine which risks are most critical and require immediate attention. High-priority risks are those with high severity and likelihood, and are usually addressed first in the mitigation process.
- Risk Mitigation: This involves developing strategies and action plans to mitigate identified risks. Mitigation strategies may include risk avoidance, risk transfer, risk reduction, or risk acceptance. Mitigation actions are documented in the RMMM plan, along with responsible parties, timelines, and resources required.
- Risk Monitoring: Risks need to be continuously monitored throughout the software development process to track their status and effectiveness of mitigation actions. This may involve regular risk reviews, progress tracking, and reporting to ensure that risks are being effectively managed and mitigated.
- Risk Management: The RMMM plan also includes ongoing risk management activities, such as periodic reviews and updates to the plan, as well as communication and coordination among stakeholders to ensure that risks are effectively addressed throughout the project’s lifecycle.
“Do you have the answer to any of the questions provided on our website? If so, please let us know by providing the question number and your answer in the space provided below. We appreciate your contributions to helping other students succeed.”